|
Ideje, hogy végre valami aktuális dologról írjak cikket, mert az eddigiekből legfeljebb annyi jött le, hogy milyen szépen lehet textúrázni egy gömböt.
Ami egy játék megírásánál semmire nem jó. A jó hír az, hogy a megvilágítás sem, mert az idő 98%-át úgyis a játéklogikával töltöd el (és a hozzá kapcsolódó lehetetlen dolgokkal, pl. fizika).
Az valahogy túl sok, úgyhogy inkább a maradék 2%-ról firkálok valamit.
Forward rendering
Mindenki unja már ezt olvasni, de akkor is leírom. Forward rendering esetében két lehetőséged van:
Ha kicsit okosabb vagy, akkor először csinálsz egy z-only pass-t, azaz csak a mélységet rajzolod ki, majd ezután végzed el a megvilágítást (D3DCMP_EQUAL-ra állítva a depthfunc-ot). Jobb kártyák a pixel shader előtt elvégzik a depth testet (early z-test). Ha még okosabb vagy, akkor felosztod a képernyőt csempékre, és csempénként meghatározod, hogy hány fény hat oda és csak annyit rajzolsz (ez egyébként deferred shadinggel is ajánlott). CODE
device.SetBlendMode(Additive);
foreach (Object o in objects)
{
foreach (Light l in lights)
o.DrawWithLight(l);
}
Csak poénból írtam C# kódot. Rögtön itt említem meg, hogy míg egy fényforrásnál eddig nyomdafestéket nem tűrő módon sosem gamma korrektáltam, több fényforrás esetén ez erősen ajánlott. Világos, hogy ha a jelenet geometriai komplexitása nagy és sok fényforrásod van, akkor a forward renderinggel lábon lőtted magad. Az ötlet az, hogy csak egyszer kelljen renderelni a geometriát, és csak egyszer a fényeket. Huh? Mutatom: CODE
foreach (Object o in objects)
o.Draw();
device.SetBlendMode(Additive);
foreach (Light l in lights)
l.Draw();
Ez már annyira elmond mindent, hogy itt abba is hagyom a cikket.
Majdnem olyan, de ferred
Azt mondta erre Saito, hogy rajzold ki a normálokat és a depthet textúrákba, és végezd el a megvilágítást postprocessként. Olyan jó ötlet volt ez, hogy majdnem 20 évet kellett várni mire
mindenki felfogta. Hehe...valójában a hardver volt béna, ugyanis ez meg azért lassú, mert baromi sok pixelre kell lefuttatni, illetve az adatok precíziója miatt a bus-t is leterheli.
Most itt jön egy agyonnyúzott ábra:
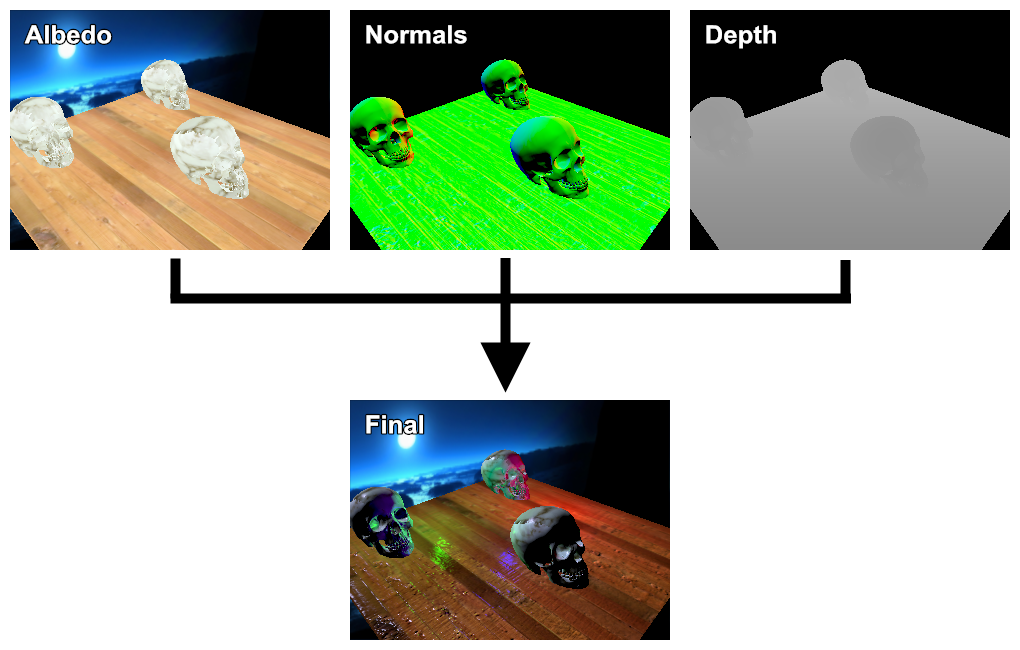
Ha gyenge videókarid van, akkor ez kapásból háromszori jelenetrajzolást jelent, aztán még plusz valamennyit (legrosszabb esetben annyit ahány fényed van). Szóval most a másik lábadat lőtted agyon. Amiben a hardver fejlődése segít, az a multiple render target, az egyre több pixel shader egység és a memória sávszél növekedése (meg persze a GPGPU, lásd Frostbite 2 engine). És persze a memória...merthogy ez bizony piszok sok memória (volt 10 évvel ezelőtt...ma már a 2 GB-os videókarik korában kutyafüle). Számoljuk csak meg: az albedónak 3 bájt (RGB8), normáloknak ha nem gondolkodsz nagyon, akkor 6 bájt (RGB16F), a depthnek 4 bájt (R32F), és persze kell a target buffer, ami megint 6 bájt, ha gamma korrektálsz. Az összesen 19 bájt, mondjuk 1920x1080-as felbontással számolva ~40 MB. És akkor még nincsenek árnyékok, HDR, meg mindenféle fölösleges dolog. Ez persze senkit nem tántorít el attól, hogy használja, mert cserébe baromi sok fényed lehet (amíg elég kicsik, nincs árnyékuk és kíméled a hardvert). Azt a sok buffert ott fent együttesen G-buffer-nek hívják (semmi köze a G-ponthoz). A G itt geometry-t akar jelenteni és szinte adódik, hogy legalább normálok és mélység kell bele. Ezeknek az előállítása természetesen multiple render target-el kell történjen, hacsak nem diavetítőre optimalizálsz. Annyit még megemlítek, hogy ha normal mappingot is akarsz, akkor a normalmapban tárolt cuccot world spacebe kell trafózni: CODE
float3 norm = tex2D(normalmapsampler, tex).rgb * 2 - 1;
float3x3 tbn = { wtan, -wbin, wnorm };
color1.rgb = normalize(mul(tbn, norm));
Megint mért kell mínusz...ez a D3DXGenerateTangentFrameEx() függvény amúgy is elég fura, mert a szimplább verziója kajak fordítva működik, mint kéne (és akkor is kell mínusz). A binormált egyébként keresztszorzattal is ki lehet számolni, szóval nem muszáj a DX-ben bízni. Nem kötelező egyébként world spaceben tárolni a normált; azt mondja a Crytek, hogy írd ki a view space-beli normál xy komponenset felszorozva a z-vel: CODE
// kiirás
color1.rg = normalize(n.xy) * sqrt(n.z * 0.5 + 0.5);
// visszaolvasás
n.z = dot(color1.rg, color1.rg) * 2 - 1;
n.xy = normalize(color1.rg) * sqrt(1 - n.z * n.z);
Némi utánaszámolással adódik, hogy a formula helyes. A fólia szerint a PS3 miatt kellett ez nekik, de én maradok inkább a world space-nél. Ezzel az input megvan, most jöhet a lényeg. Egyesek olyat csinálnak, hogy a world space pozíciót is kirenderelik a gbufferbe. Ne tedd! Ez ugyanis baromi egyszerűen visszaszámolható: CODE
uniform matrix matViewProjInv;
// ...
float d = tex2D(depthsampler, tex).r;
float4 wpos = float4(tex.x * 2 - 1, tex.y * -2 + 1, d, 1);
wpos = mul(wpos, matViewProjInv);
wpos /= wpos.w;
Ahol tex a szokásos fullscreen quad texcoordja. A Crytek erre is ad egy olcsóbb módszert: CODE
float d = tex2D(depthsampler, tex).r;
float3 wpos = eyePos + d * vdir;
Ahol d most lineáris, vdir pedig a kamera pozíciójából a távoli vágósíkjának négy sarkába mutató vektor (interpolálva a screenquad-on). Höfö megcsinálni. Innentől kezdve pedig minden ugyanúgy megy, mint eddig. Azaz majdnem...
Ez itt pont fény...pont egy fény
Mivel olyan költséges dolog a pixel shadert futtatni, nem kéne fölöslegesen. Egy pont fény általában nem világít a végtelenségig.
A szép elhalványításhoz az alábbi algoritmust implementáltam le (az eredeti cikk nem érhető már el):
CODE
float Attenuate(float3 ldir)
{
ldir /= lightPos.w;
float atten = dot(ldir, ldir);
float att_s = 15;
atten = 1.0f / (atten * att_s + 1);
att_s = 1.0f / (att_s + 1);
atten = atten - att_s;
atten /= (1.0f - att_s);
return saturate(atten);
}
Egy tipikus hiba, hogy ha nem használsz gamma korrekciót, akkor a lineáris változat (atten = distance / lightrange) ad jobb eredményt, ugyanis a gamma hatványra való emelés (ami tipikusan 2.2) majdnem egybeesik a négyzetre emeléssel (és a valóságban olyan). Ez azonban hiba, úgyhogy tessék gamma korrektálni. Na de ez még önmagában nem old meg semmit, ha viszont tudjuk, hogy a fény csak adott sugarú környezetben világít, akkor ki lehetne számolni, hogy a képernyőn mely pixelekre kell lefuttatni a shadert. Ehhez egy téglalapot kell megadni, és a scissor test az ezen kívülre eső pixeleket kidobja. Ennek kiszámolását ez a cikk szépen le is vezeti, de némi meggondolást hozzá kell tenni: Ha megvan az érintősík normálvektora, akkor abból az érintési pont könnyen megvan, ugyanis P = L - r N. A másik észrevétel, hogy az e-val való varacskolás fölösleges (bár hatékonyabb), mert tipikusan úgyis csak a projekciós mátrixot tudod. Ekkor viszont Q = P * matProj ahonnan w-vel való osztás után megkapható a scissor rect koordinátája screen spaceben. A harmadik észrevétel pedig, hogy DX-ben az y screen space-beli koordináta a [1, -1] tartományban van, tehát -0.5-el kell szorozni. Egy másik megoldás erre, hogy kirajzolsz egy gömböt és projektív textúrázással olvasol a gbufferből. Pixel shader szempontból ez jobban hangzik, sőt implementálni is könnyebb pl. spot lightokra (gömb helyett valami kúpszerű vacakkal). Arra viszont figyelni kell, hogy ha a kamera a gömbön belül van, akkor a back faceket rajzold. A fényekre szintén érdemes view frustum culling-ot alkalmazni, ez pont fényeknél nagyon egyszerű, hiszen 6 darab skaláris szorzás és 6 darab összehasonlítás (ne felejtsd el, hogy a frustumon kívül még van egy r vastag elfogadási zóna).
Problémák a módszerrel
Először is MSAA-val értelmetlen, hacsak nem minden buffer MSAA-s. Na de az már tényleg pazarlás. Ha meg nem, akkor rezolválás után történhet csak a megvilágítás, ami elrontja az antialiasolt képet.
Inkább post-AA (de az egy másik cikk). Hasonlóan a memóriahasználat miatt kompromisszumokat kell tenni arra nézve, hogy milyen egyéb adatot írsz ki (material színek: diffuse, specular, emissive, etc.).
Szerintem egy material ID még nyugodtan elfér (jó esetben 1 bájt), persze az hogy a shaderben hogyan dolgozod fel az már más kérdés... Megint csak, manapság ez már nem akkora probléma.
Deferred lighting
Milyen előnyei vannak annak, ha a megvilágítást (diffuse és specular) előre kiszámolod? Például az, hogy ehhez elég csak a fent említett normál és depth buffer (illetve a shininess faktor).
Ez után viszont a jelenetet mégegyszer kirajzolhatod, immár textúrával/material tulajdonságokkal, az irradiance-t pedig kiolvasod az előbb készített textúrákból.
Ez egy lényeges memóriacsökkentés. A még jobb hír, hogy MSAA-t is használhatsz (részben; a megvilágítás nem lesz MSAA-s).
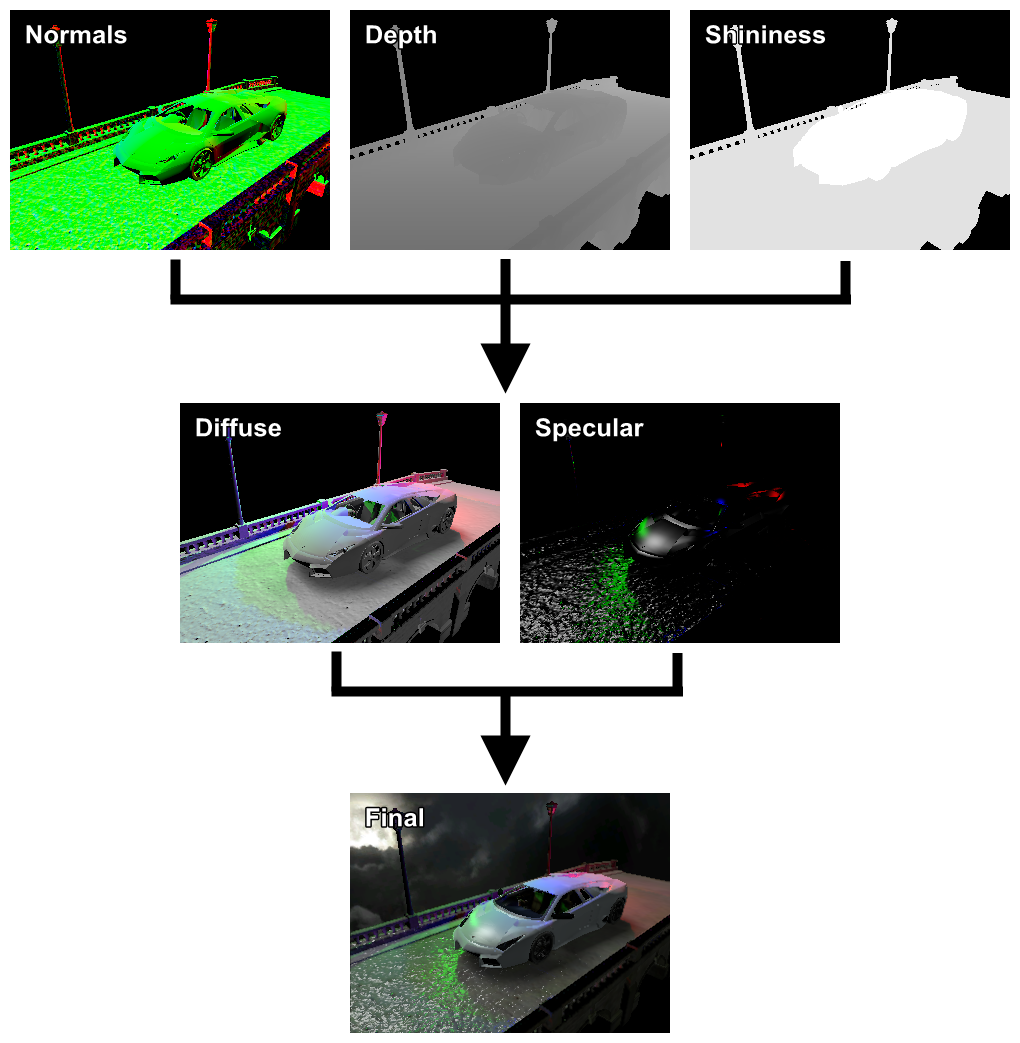
Szemfüles érdeklődőknek feltűnt, hogy nincs albedó. Dehogynemnincs, a harmadik pass egy második "forward" pass, amiben immár uniformként lepasszolható a textúra, material tulajdonságok, stb. A kirenderelt irradiance-t pedig projektív textúrázással olvassa. Na de akkor mennyit is spóroltunk ezzel? Normálok + shininess ARGB16F, depth még mindig R32F és a két akkumuláló buffer is ARGB16F. Ez összeadva 55 MB, MSAA-val még plusz 64 MB (ha a végső buffert AA-zod csak). Szóval azt lehet mondani, hogy egy dupla renderelés árán a memóriahasználat lényegesen kisebb és nem függ material tulajdonságoktól. Mivel ez ilyen, tükröződést is lehet vele használni. Az viszont nem trivi kérdés, hogy a cubemapet hogyan állítsad elő. Én azt mondom, hogy azt is deferred lighting-al, mert egyrészt minimális extra kódolás, másrészt nem is kell neki külön gbuffer, mert úgyis kisebb, mint a rendes, akkor meg lehet használni azt (viewport állítással). Kérdés, hogy megéri-e? Egyáltalán megéri-e maga a deferred rendering (hiszen eleve az elérhető fps negyedéröl indul)? Az átlátszó objektumoknak még mindig kell egy forward renderer, szóval nem úszod meg a két külön pipeline karbantartását. Sőt, a gbuffer elkészítése miatt az első pass igen költséges (fillrate), azaz ha kevés fényed van, akkor már nem érte meg. A gbufferből való olvasás szintén költséges (memory bandwidth).
Compute shader alapú módszerek
Részletesen erről most nem írok, mert egy külön cikkben lesz róla szó. A lényege ezeknek az, hogy a képernyőt felosztod csempékre, majd egy compute shader mindegyik csempére meghatározza, hogy mely fények hatnak oda.
Ez lehetővé teszi, hogy drasztikusan több fényforrást használhass (akár ezernél is többet; de komolyan, melyik játékba kell annyi?). Ha most az előző forward rendereres példakódot tekintjük, akkor az így módosulna (forward+):
CODE
DispatchCompute(...);
device.SetBlendMode(Additive);
foreach (Object o in objects)
{
// a fényekre vonatkozó ciklus pedig a shaderben
o.Draw();
}
A módszer előnye egyben hátránya is: tényleg csak akkor van haszna, ha nagyon sok fényed van. Deferred shadinggel/lightinggal is ugyanúgy használható, sőt talán gyorsabb is (de akkor megint buktad az MSAA-t). A cikk kódjai között már megtalálható a forward+ renderer implementációja, de OpenGL 4.3-as kártya kell hozzá.
Megjegyzések a kódhoz
A második példaprogiban a híd is X fájl volt, de baromi lassan töltötte be (release módban is). Bár az X formátumnak is van bináris változata, az legacynak számít és nekem egyébként se működik soha.
Szóval inkább áthoztam a Quadron mesh formátumát. Illetve bizonyos dolgokat most már kivittem egy közös részbe, amit szentimentálisan dxext.h-nak neveztem el.
Summarum
Most sem kíméltem a videókarit, nálam a program alig 50 FPS-en fut.
Csak deferred renderingre semmiképpen nem szabad építeni, egyrészt mert amúgyis kell mellé egy forward renderer, másrészt sok esetben az a jobb (pl. amikor a szabadban vagy, hiszen ott csak egy darab fényforrás van).
Tehát az enginet úgy kell kialakítani, hogy mindkettővel működjön (és pixelre ugyanúgy nézzen ki). Hasznos dolgokat lehet olvasni deferred renderingről a GPU Gems-ben.
A táblázat picit csal, mert ha árnyékot is akarsz, akkor mindenképpen optimalizálnod kell. Deferred renderinggel viszont elég limitált, hogy hány ilyen fényforrást engedhetsz meg magadnak (főleg ha pont fény). Általában a nagy fények hülyén néznek ki árnyék nélkül, de én erre azt mondom, hogy ha a közelében van egy árnyékot vető másik fény, akkor nem feltűnő. Szóval pont fényeket inkább eyecandy-hez használj és ne direkt megvilágításhoz. Egy szó a gamma korrekcióról: ne a gbuffer rajzoláskor hatványozd az albedót, mert az RGB8 formátum nem tudja jól tárolni (tudjuk miért, ld. HDR-es cikk). Kód itt, videó itt és itt.
Höfö:
|


