|
Tavaly év vége felé, amikor az első hírek röppentek fel a Vulkan-ról (nevezetesen az, hogy késni fog) én csak vidáman legyintettem az egészre, hogy "jólvan kihoznak egy Mantle klónt, azt is késve, ugyan ki fogja ezt használni?". Főleg, mert addigra elérhető volt a DirectX 12 és a Metal is (hacsaknem dokumentáció szinten), emiatt akkor úgy tűnt, hogy a Vulkan-t legfeljebb Android/Linux-on fogják használni, így ezt a cikket is kifigurázó hangvételűnek terveztem.
Tartalomjegyzék
A 3D grafika nagy elméleti problémái (fotorealizmus) után kicsit gyakorlatiasabb vizekre evezünk, amit úgy lehet megfogalmazni, hogy "hát szép-szép ez a pónilósimogató játék, de nem lehetne gyorsabb?" A problémának (vagy inkább elérendő célnak) neve is van: AZDO, azaz Approaching Zero Driver Overhead. Ezt nem most találták ki, már OpenGL-hez is van egy rakat trükk, amivel el lehet érni; a vulkán viszont kimondottan erre épít.
A vulkán tehát új fejlesztésekhez ideális, na de miért lesz tőle gyors a program? Röviden azért, mert az OpenGL-el szemben több szálból is használható, nagyon minimális ellenőrzéseket csinál, nem foglalkozik memóriakezeléssel és szintén nem foglalkozik a rajzolóparancsok egymás közti függőségeivel. Ez egyben azt is megindokolja, hogy mitől olyan nehéz (newsflash): azért mert mindezeket neked kell megcsinálnod. Demotiváló ábra következik: 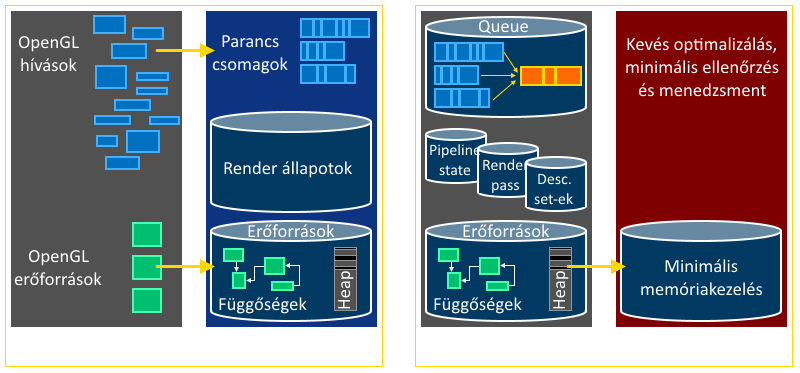
Ez egy hasonló ábra az nVidia prezentációjában megtalálhatóhoz, de kicsit Csak egy példa: a kód tele van pipeline barrier-ekkel, ugyanis explicit meg kell váratnod a driverrel amíg írhatóvá/olvashatóvá válik mondjuk egy textúra. Később érthető lesz, hogy ennek fényében a Metal-t miért nem tekintem alacsony szintűnek (röviden: mert bár állításuk szerint AZDO, mégis rengeteg ilyen dolgot elfed). Az a tény, hogy a vulkán mindent a kezedbe ad, magával hozza azt a kellemetlen apróságot is, hogy az égvilágon mindent előre meg kell neki mondanod: melyik render subpass hogyan módosítja majd az attachment-jeit, milyen parancsokat fogsz azon belül meghívni, milyen shaderek lesznek beállítva, azokhoz milyen bufferek lesznek bebindolva, a textúrák milyen layout-ban lesznek, etc. etc. Ne értsük félre: ez indokolt, hiszen a korábbi API-kban sok ilyen változtatgatás a shader implicit újrafordítását eredményezte! A nehézség két dologból tevődik tehát össze: közvetlen szinkronizáció és rengeteg kódolás. De hát azt mi szeretjük, nem? Az elinduláshoz először is telepíteni kell egy megfelelő (a cikk írásának pillanatában béta) drivert (nVidia, AMD). Nekem a GTX 650-en ez telepítés közben mindig lefagyott; csak úgy tudtam felrakni, hogy safe mode-ban letöröltem a régit. Ha programozni is szeretnél, akkor szükség van még a LunarG SDK-ra (ezt minden driver frissítés után rakd újra!), és a cmake-re (mert bizony néhány dolgot neked kell lefordítani). A cikk kódjába én minden szükséges dolgot bepakoltam, úgyhogy ezt a lépést megúsztátok (szívesen). Zárójelben mondom, hogy a vulkános példaprogijaim csak 64-bitesek (bár nem követelmény, de célszerű...).
CODE
VkInstance instance = 0;
CODE
VkApplicationInfo app_info = {};
VkInstanceCreateInfo inst_info = {};
VkResult res;
app_info.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
app_info.pNext = NULL;
app_info.pApplicationName = "Asylum's Vulkan sample";
app_info.applicationVersion = 1;
app_info.pEngineName = "Asylum's sample engine";
app_info.engineVersion = 1;
app_info.apiVersion = VK_API_VERSION_1_0;
inst_info.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
inst_info.pNext = NULL;
inst_info.flags = 0;
inst_info.pApplicationInfo = &app_info;
// ...
res = vkCreateInstance(&inst_info, NULL, &instance);
assert(res != VK_ERROR_INCOMPATIBLE_DRIVER);
Ez a kód egyben recept is a továbbiakhoz: minden vulkán struktúra szigorúan típusos, illetve az extension-ök számára fenntart egy pNext pointert. Ahogy a hagyma és az ogre, úgy a vulkán is rétegekből épül fel. A legalsó réteg nyilván a vulkan core layer, ami önmagában nagyon minimális ellenőrzéseket csinál csak, így roppant egyszerűvé vált a számítógép lefagyasztása (erősen javaslom, hogy rakjál __debugbreak()-et a debug callback-be). Szerencsére a feltelepített SDK-ban mellékelve van a LunarG standard validation layer. Nézzük meg hogyan kell ezt beüzemelni: CODE
const char* instancelayers[] = {
"VK_LAYER_LUNARG_standard_validation"
};
const char* instanceextensions[] = {
"VK_KHR_surface",
"VK_KHR_win32_surface",
"VK_EXT_debug_report" // hasonló, mint OpenGL-ben
};
inst_info.enabledLayerCount = ARRAY_SIZE(instancelayers);
inst_info.ppEnabledLayerNames = instancelayers;
inst_info.enabledExtensionCount = ARRAY_SIZE(instanceextensions);
inst_info.ppEnabledExtensionNames = instanceextensions;
// ...
Egy kalap alá vettem a szükséges extension-ök beállításával. Persze nem biztos, hogy az adott réteg jelen van, ezért úgy tisztességes, hogy előbb lekérdezed a vkEnumerateInstanceLayerProperties() függvénnyel (ehhez nem kell még az instance, szemben az OpenGL-el). A következő lépésben a fizikai hardverektől (physical device) megkérdezzük a tulajdonságaikat, kiemelten kezelve hogy milyen command queue-kat tudnak, illetve ezek közül melyik alkalmas rajzolásra. A metállal szemben a vulkános command queue-kat tehát a hardver adja, és a majdani (logical) device-al együtt kell létrehozni. Ilyen "hardware queue"-ból a szabvány többfélét enged meg:
A vulkán tehát erősen gépfüggő, ami tovább bonyolítja a fejlesztést (erre később több példa is lesz). De nézzük most a hardver tulajdonságainak lekérdezését: CODE
VkPhysicalDeviceFeatures devicefeatures;
VkPhysicalDeviceProperties deviceprops;
VkPhysicalDeviceMemoryProperties memoryprops;
uint32_t gpucount = 0;
uint32_t queuecount = 0;
CODE
vkEnumeratePhysicalDevices(driverinfo.inst, &driverinfo.gpucount, 0);
VkPhysicalDevice* gpus = new VkPhysicalDevice[gpucount];
vkEnumeratePhysicalDevices(driverinfo.inst, &gpucount, gpus);
// most feltételezem, hogy az első kell, de kódban ezt ellenőrizni illik
vkGetPhysicalDeviceQueueFamilyProperties(gpus[0], &queuecount, 0);
VkQueueFamilyProperties* queueprops = new VkQueueFamilyProperties[queuecount];
vkGetPhysicalDeviceQueueFamilyProperties(gpus[0], &queuecount, queueprops);
// ezek nélkül nem lehet élni
vkGetPhysicalDeviceFeatures(gpus[0], &devicefeatures);
vkGetPhysicalDeviceProperties(gpus[0], &deviceprops);
vkGetPhysicalDeviceMemoryProperties(gpus[0], &memoryprops);
Célszerű mindent megtartani, illetve összeszedni egy (jó nagy...) struktúrába. Nem akarok túl sok kódot írni, úgyhogy a további lépéseket csak felsorolom (ha megnézitek a kódot, akkor megértitek, hogy miért):
Mindenkinek figyelmébe ajánlom a VkPhysicalDeviceProperties::limits adattagot, azon belül is a maxMemoryAllocationCount mezőt (melynek értéke desktopon(!) 4096). Vége van ugyanis az OpenGL-ben előszeretettel alkalmazott orbitális mennyiségű resource létrehozásnak: a vulkán rákényszerít a szuballokációra illetve a resource aliasing-ra (több erőforrás ugyanazt a memóriaterületet használja). A következő N bekezdésben megmutatom hogyan kell eljutni a rajzolásig, majd néhány bónusz bekezdésben részletezem, hogy mit hogyan érdemes használni. A cikk végén megtalálható a fogalmak összefoglaló listája. Amint az előző bekezdésben megbeszéltük, a vulkán központi objektuma a device, ami elérhetőséget biztosít egy vagy több queue-hoz, amik akár párhuzamosan is dolgozhatnak egymáshoz képest. Létrehozáskor megadható az egyes queue-k prioritása, ami alapján a driver több számítási kapacitást ad a fontosaknak.
Egy queue-nak nincs túl sok művelete: "dolgozz" és "várj". Amikor munkát adunk a queue-nak az egy command buffer leküldését jelenti, igény esetén szinkronizációs objektumokkal ("várj előbb ezekre", "szólj ha kész vagy vele").
CODE
VkCommandBuffer commandbuffer = 0;
VkCommandBufferAllocateInfo cmdbuffinfo = {};
VkCommandBufferBeginInfo begininfo = {};
VkSubmitInfo submitinfo = {};
// allocate
cmdbuffinfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
cmdbuffinfo.pNext = NULL;
cmdbuffinfo.commandPool = commandpool;
cmdbuffinfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
cmdbuffinfo.commandBufferCount = 1;
vkAllocateCommandBuffers(device, &cmdbuffinfo, &commandbuffer);
// record
begininfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
begininfo.pNext = NULL;
begininfo.flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT;
begininfo.pInheritanceInfo = NULL;
vkBeginCommandBuffer(commandbuffer, &begininfo);
{
// TODO: parancsok
}
vkEndCommandBuffer(commandbuffer);
// submit
submitinfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submitinfo.pNext = NULL;
submitinfo.waitSemaphoreCount = 0; // nem várunk senkire
submitinfo.pWaitSemaphores = NULL;
submitinfo.pWaitDstStageMask = NULL;
submitinfo.commandBufferCount = 1;
submitinfo.pCommandBuffers = &commandbuffer;
submitinfo.signalSemaphoreCount = 0; // nem értesítünk senkit
submitinfo.pSignalSemaphores = NULL;
vkQueueSubmit(graphicsqueue, 1, &submitinfo, VK_NULL_HANDLE); // "dolgozz"
vkQueueWaitIdle(graphicsqueue); // "várj"
vkFreeCommandBuffers(device, commandpool, 1, &commandbuffer);
Ez a kódrészlet használható lehetne rajzoláskor is (a command buffer létrehozása/törlése nagyon hatékony), de én csak az inicializáló részben használom transfer műveletekhez. A rajzolásnál kicsit bonyolultabb a helyzet, mert szinkronizációs objektumokat is célszerű használni (a frame queueing érdekében). A Vulkan legnagyobb előnye a Metal-hoz képest, hogy a command buffer-ek előre legyárthatóak és tetszőlegesen sokszor leküldhetőek. Ennek hozadékait külön bekezdésben ismertetem. Nagyon kritikus hogy megértsük, mert ezek nélkül nincs élet vulkánban. Négy ilyen objektum van, mindegyik más-más célt szolgál:
A vkQueueWaitIdle() függvény ekvivalens egy fence-el, ami végtelen ideig várakozik, előbbit az irodalmak mégsem használják. A cél ugyanis az, hogy ne kelljen bevárni az összes command buffer befejeződését, hanem ami kész van, azt rögtön kezdjük el újra feltölteni. Alakítsuk át a fenti kódot, hogy később bővíthető legyen command buffer átfedésekre: CODE
VkCommandBuffer commandbuffer = ...;
VkSemaphore framesema = ...;
VkFence drawfence = ...;
CODE
// rajzolás
VkCommandBufferBeginInfo begininfo = { ... };
VkSubmitInfo submitinfo = {};
// jelez a szemafornak amikor a prezentáció befejezte az olvasást (ld. Frame queueing)
vkAcquireNextImageKHR(device, swapchain, UINT64_MAX, framesema, NULL, ¤timage);
vkResetCommandBuffer(commandbuffer, 0);
vkBeginCommandBuffer(commandbuffer, &begininfo);
{
// TODO: parancsok
}
vkEndCommandBuffer(commandbuffer);
VkPipelineStageFlags pipestageflags = VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT;
submitinfo.waitSemaphoreCount = 1;
submitinfo.pWaitSemaphores = &framesema; // várunk a prezentálóra
submitinfo.pWaitDstStageMask = &pipestageflags; // hol várunk (pipeline vége)
vkResetFences(device, 1, &drawfence);
vkQueueSubmit(graphicsqueue, 1, &submitinfo, drawfence);
// most egyelőre megvárom amíg befejeződik
vkWaitForFences(device, 1, &drawfence, VK_TRUE, 100000000);
Vulkánban tehát a fence tölti be a metálban használt szemafor szerepét. Vigyázat, a vkQueueSubmit()-ban megadott fence akkor lesz csak értesítve, amikor az összes (abban az egy hívásban) leadott command buffer befejeződött! A prezentálást a frame queueing-al együtt ismertetem egy későbbi bekezdésben. Hátravan még a leggyakrabban használt szinkronizációs objektum: a barrier. Ebből háromféle is van:
Az egyik indok az alacsony szintű programozás mellett az, hogy a hardver számára optimális helyre és alignment-el lehet elhelyezni az erőforrásokat, amiket aztán a resource aliasing által több célra is fel lehet használni (pl. egy már nem használt buffer memóriaterületét felhasználni valami rajzolásra).
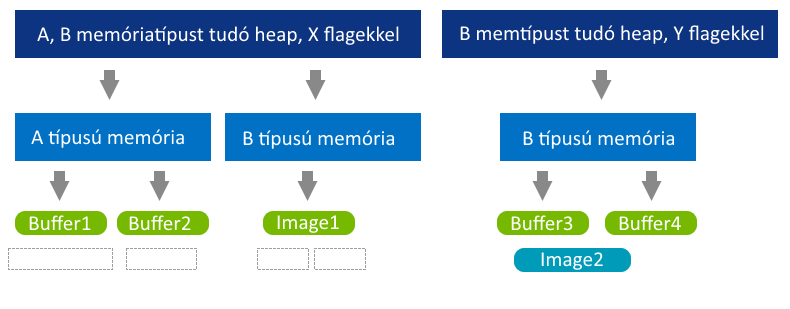
Az ábrán próbáltam jelezni, hogy nem foglalható akárhova buffer után image. Van ugyanis egy buffer-image granuality nevű hardverfüggő tulajdonság, ami megmondja, hogy milyen offset-re lehet lineáris adat után optimális adatot foglalni (később). De ha megtaláltad a neked tetsző memory heap-et, akkor foglalhatsz belőle memóriát és hozzákötheted egy buffer-hez vagy image-hez. Nézzük meg: CODE
VkBuffer buffer = 0;
VkDeviceMemory memory = 0;
CODE
VkBufferCreateInfo buffercreateinfo = { ... };
VkMemoryAllocateInfo allocinfo = { ... };
VkMemoryRequirements memreqs;
VkFlags flags = VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT;
buffercreateinfo.usage = VK_BUFFER_USAGE_UNIFORM_BUFFER_BIT;
vkCreateBuffer(device, &buffercreateinfo, NULL, &buffer);
vkGetBufferMemoryRequirements(device, buffer, &memreqs);
// implementációhoz ld. kód
allocinfo.memoryTypeIndex = GetMemoryTypeForFlags(memreqs.memoryTypeBits, flags);
allocinfo.allocationSize = memreqs.size;
vkAllocateMemory(device, &allocinfo, NULL, &memory);
vkBindBufferMemory(device, buffer, memory, 0);
Ez egy teljesen veszélytelen buffer (nem biztos, hogy a GPU-n van lefoglalva!), amire meg lehet hívni a vkMapMemory() függvényt és a visszakapott pointerbe lehet írni. Ha befejezted az írást, akkor (előbb) meghívod a vkFlushMappedMemoryRanges() függvényt, hogy a device számára látható legyen a módosítás, majd unmappeled. Vigyázat, a mappelés nem skatulyázható! Ha megadod még a VK_MEMORY_PROPERTY_HOST_COHERENT_BIT flaget is, akkor a pointer permanensen írható/olvasható marad, nem kell se unmappelni se flusholni. Ez persze kényelmes, de rendszermemóriából igen lassú rajzolni. Ha az eszköz tud megosztott memóriát, akkor megadva még a VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT flaget máris javul a teljesítmény. De mint mondtam nem minden kártya tud ilyet, speciel az enyém sem. Ilyenkor az a megoldás, hogy csinálsz egy átmeneti staging buffer-t (VK_BUFFER_USAGE_TRANSFER_SRC_BIT-et ne felejtsd el megadni!), illetve egy csak device oldali tényleges buffert (VK_BUFFER_USAGE_TRANSFER_DST_BIT). A GPU-ra felmásoláshoz szükség van egy command buffer-re: CODE
VkBufferCopy region;
region.srcOffset = 0;
region.dstOffset = 0;
region.size = buffsize;
vkCmdCopyBuffer(commandbuffer, stagingbuffer, buffer, 1, ®ion);
A végrehajtási modellnél megbeszéltek alapján ez a kódrészlet az inicializálós command buffer-be pakolható. A vkQueueWaitIdle() után a staging buffer törölhető is (hacsaknem később szükség van rá). A buffer usage-nek több értéket is össze lehet vagyolni, tehát például ugyanazon buffer tartalmazhat vertex, index és uniform adatokat is, megfelelő offseteléssel. Sőt, az nVidia kimondottan javasolja, hogy ezt tedd, mert akkor a kártya szeretni fog. Nekem ezt nem sikerült igazolni. Van két furcsa buffer típus, amiket még OpenGL-ből örökölt a vulkán: uniform texel buffer illetve storage texel buffer. Ez olyan buffer-t jelent, ami mintavételezhető (GLSL: samplerBuffer); a következő bekezdésből kiderül, hogy miért létezik egyáltalán ilyen. Ahhoz, hogy használni lehessen, csinálni kell hozzá egy buffer view-t, ami megmondja, hogy milyen formátumban kell értelmezni az adatot. Külön bekezdésbe vettem, mert kissé eltér a buffer-ek kezelésétől, merthogy a textúrák nem lineáris módon vannak tárolva. Gondoljunk bele abba, hogy (lineáris tárolást feltételezve) amikor egy mintavételező olvasni akar a textúrából, akkor a texel bal és jobb szomszédját könnyen eléri, az alsó/felső szomszédja viszont bent sincs a cache-ben.
CODE
VkBufferImageCopy region;
region.bufferOffset = 0;
region.bufferRowLength = 0; // ha 0, akkor tightly packed-nek tekinti
region.bufferImageHeight = 0; // ha 0, akkor tightly packed-nek tekinti
region.imageOffset = { 0, 0, 0 };
region.imageExtent = { width, height, depth };
region.imageSubresource = ...;
vkCmdCopyBufferToImage(
commandbuffer, stagingbuffer, image, VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, 1, ®ion);
Fordított eset is lehetséges: például amikor egy rendertarget tartalmát vissza szeretnéd olvasni. Olyankor célszerűbb a vkCmdCopyImage() parancsot használni. Multisampling esetén ezek nem működnek, olyankor rajzolással/blitteléssel lehet mozgatni az adatot. Az image-ek egy másik tulajdonsága a felhasználási cél (usage), ami a buffer usage-hez hasonlóan kombinálható flagek halmaza. Hardverfüggő viszont, hogy melyik usage-hez milyen formátumok vannak támogatva és még további megszorítások is lehetnek, mint pl. memóriatípus, felbontás, stb. Gyakori hiba egy adott usage érvénytelen használata (pl. a fenti példa nem használható rendertarget-ként!). Talán a legnehezebb fogalom image-ek esetén a layout tulajdonság. Létrehozáskor ez lehet VK_IMAGE_LAYOUT_UNDEFINED, vagy VK_IMAGE_LAYOUT_PREINITIALIZED, amennyiben rögtön fel is töltötted (nem a fenti kóddal). Ezen kezdeti layout-al konkrétan semmit nem lehet kezdeni, a használathoz szükség van egy layout transition-re. Mondok jobbat: bármikor amikor változik az image felhasználási célja, akkor azt egy layout transition-nel kell elvégezni (tehát a fenti kód esetén is!). Kódban ez a következőképpen fest (a fenti kód előtt): CODE
VkImageMemoryBarrier barrier = {};
barrier.srcAccessMask = 0; // még csak létrejött
barrier.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT; // írni akarom
barrier.oldLayout = VK_IMAGE_LAYOUT_UNDEFINED;
barrier.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
barrier.image = image;
barrier.subresourceRange = ...;
vkCmdPipelineBarrier(
commandbuffer,
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, // ezek előbb fejeződjenek be (pipeline eleje)
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, // ezek még ne kezdődjenek el (később lesz róla szó)
0, 0, NULL, 0, NULL, // másfajta barrier most nincs
1, &barrier);
Hasonlóan lehet elérni, hogy a textúra olvasható legyen shaderből (VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL), figyelembe véve, hogy mi volt a korábbi layout. Hogy hogyan az egy külön bekezdés... Vigyázat, bizonyos példaprogramok VK_IMAGE_LAYOUT_UNDEFINED-et adnak meg oldlayout-nak azt feltételezve, hogy a driver majd figyelmen kívül hagyja, de a szabvány szerint ez azt jelenti, hogy az adat nem érdekel (és így nem köteles megtartani). Szóval tárold el a régi layout-ot (és az access mask-ot is)!. Még nagyobb vigyázat: az nVidia nem implementálja a layout transition-t! Nehogy kiadd úgy a programodat, hogy nem tesztelted más kártyákon (sőt talán az a legjobb, ha AMD kártyán fejlesztesz)! Érdemes tudni, hogy a GPU on the fly módon átrendezheti illetve tömörítgetheti ki/be az adatot (delta color compression), ami layout transition-kor történik meg. Ennek vannak bizonyos teljesítményvonzatai, amikről itt lehet olvasni. Annyit még elmondok, hogy shader esetén nem maga a textúra lesz beállítva, hanem egy image view. Ez több dologra is használható:
Metálban a render pass tulajdonképpen a framebuffer volt, vulkánban viszont kicsit eltér ettől például azért, mert külön van VkFramebuffer objektum. Utóbbi tulajdonképpen csak egy image view-okból álló halmaz. Az összefüggésekről egy ábra:
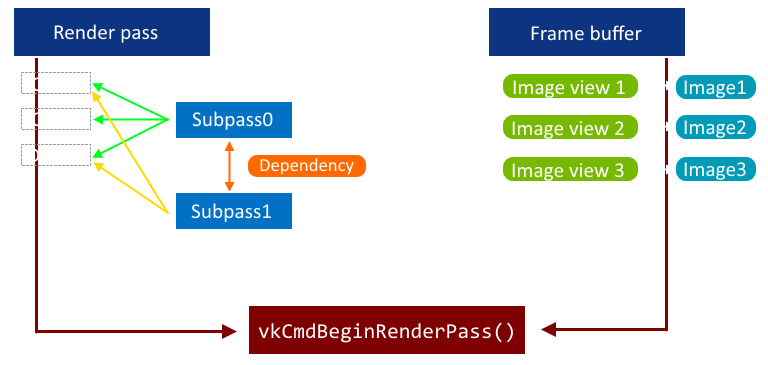
Vulkánban a render pass egy lista az azon belül használt attachment-ek néhány adatáról (formátum, multisampling) illetve felhasználási módjáról (load/store action). Ezeket az attachment-eket utána halmazokba (render subpass) lehet válogatni, ahogy az ábra is mutatja. Újdonságnak tekinthetőek az ún. input attachment-ek, amikből a fragment shader közvetlenül tud adatot betölteni. Például egy adott subpass eredménye lehet a következő subpass inputja, amivel nyilván spórolunk, mert egyáltalán nem kell mintavételező. Sőt, mobil GPU-kon ez közvetlenül a tile local storage-ből olvas! CODE
layout (input_attachment_index = 0, binding = 1) uniform subpassInput input1;
void main()
{
vec4 color = subpassLoad(input1);
}
Egy másik fogalom a preserve attachment, ami annyit mond, hogy az adott subpass ugyan nem használja azt az attachment-et, de egy későbbi majd igen, úgyhogy tartsa meg a driver. A subpass-ok között (sokszor kötelezően) meg lehet adni függőséget (dependency), ami valójában egy implicit barrier (hasonlóan is kell kitölteni). Bármily meglepő egy subpass-nak lehet függősége render pass-on kívüli dolgokkal is, sőt saját magával is! Idézet a szabványból:
"If vkCmdPipelineBarrier is called within a render pass instance, the render pass must declare at least one self-dependency from the current subpass to itself."
Illetve egy csomó további feltétel is. Mivel a barrier ilyen szigorú megszorításokkal van kezelve érthető, hogy miért redundáns itt az API. De mit jelent a self-dependency és az external dependency, illetve egyáltalán mit ír le egy tetszőleges subpass dependency? Két dolgot rögzítenek ezek le (és értsük ugyanezt barrier-ek esetén is!):
CODE
VkSubpassDependency dependency = {};
dependency.dependencyFlags = 0;
// "subpass 0 rajzol a depth attachment-be, de a fragment operációk legyenek készen -"
dependency.srcSubpass = 0;
dependency.srcAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
// "- mielőtt subpass 1-ben a vertex shader elkezdené olvasni"
dependency.dstSubpass = 1;
dependency.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
dependency.dstStageMask = VK_PIPELINE_STAGE_VERTEX_SHADER_BIT;
A függőség érvényes lehet ún. régiónként is, ami alatt a szabvány szerint pixelt kell érteni (de implementációfüggő, hogy mit jelent). Ebben az esetben a végrehajtási függőség ezen régiókra egyesével kell érvényesüljön és nem globálisan. Később is meg fogom említeni, de akkor kell ezt megadni, ha a függőség framebuffer stage-ekre vonatkozik. A framebuffer-t és a render pass-t összerakva kezdődhet el az első subpass a vkCmdBeginRenderPass() függvény által. A további subpass-okba a vkCmdNextSubpass() függvénnyel lehet belépni. Ezen két függvénynek a legfontosabb paramétere a subpass contents, ami azt mondja meg, hogy mi történhet a subpass-on belül:
A rajzolás befejezése a vkCmdEndRenderPass() függvénnyel történik. Egy jó példa render subpass-ok használatára a deferred shading. Az első subpass a g-buffer-t tölti fel, a második pedig azt felhasználva az akkumuláló textúrákat. A kettő közötti függőség nyilván write/read típusú (mint az ábrán). Kis küzdelem volt ez, merthogy az assembler csak Visual Studio 2015-től fölfelé fordul. Értitek, C interfész és C++11 van mögötte...tök logikus. Véleményemet frappáns kétszavas mondatokban fejeztem ki a fejlesztőnek.
Na de, ha mindannyian lenyugodtunk, akkor nézzünk egy egyszerű kis texúrázós fragment shader-t:
CODE
OpCapability Shader
%1 = OpExtInstImport "GLSL.std.450"
OpMemoryModel Logical GLSL450
OpEntryPoint Fragment %main "main" %outColor %tex
OpExecutionMode %main OriginUpperLeft
; annotációk
OpDecorate %outColor Location 0
OpDecorate %sampler1 DescriptorSet 0
OpDecorate %sampler1 Binding 1
OpDecorate %tex Location 0
; uniform, in, out
%void = OpTypeVoid
%3 = OpTypeFunction %void
%float = OpTypeFloat 32
%v4float = OpTypeVector %float 4
%_ptr_Output_v4float = OpTypePointer Output %v4float
%outColor = OpVariable %_ptr_Output_v4float Output
%10 = OpTypeImage %float 2D 0 0 0 1 Unknown
%11 = OpTypeSampledImage %10
%_ptr_UniformConstant_11 = OpTypePointer UniformConstant %11
%sampler1 = OpVariable %_ptr_UniformConstant_11 UniformConstant
%v2float = OpTypeVector %float 2
%_ptr_Input_v2float = OpTypePointer Input %v2float
%tex = OpVariable %_ptr_Input_v2float Input
; függvények
%main = OpFunction %void None %3
%5 = OpLabel ; blokk eleje
%14 = OpLoad %11 %sampler1
%18 = OpLoad %v2float %tex
%19 = OpImageSampleImplicitLod %v4float %14 %18
OpStore %outColor %19
OpReturn ; blokk vége
OpFunctionEnd
Most miért néztek így? Ez a SPIR-V, a vulkán shader nyelve; pontosabban annak az assembly-szerű változata (merthogy maga a SPIR-V bináris). Jogos felvetés, hogy ha GLSL-ből is lehet SPIR-V-t fordítani, akkor miért küszködnénk ilyen érthetetlen kódokkal? Nem kell...amíg a glslang (vagy a ShaderC) le tudja fordítani amit szeretnél... Beszéljük azért át, hogy mi micsoda. Maga a bináris program egy (SPIR-V) modul. Az amit a modul használ, azt ő képességnek (capability) nevezi. A futtatókörnyezetnek ezeket a képességeket támogatnia kell. Bizonyos képességek függenek egymástól, így pl. a Shader képesség magával rántja azt is, hogy tudsz mátrixokat használni. (- Használhatok mátrixokat??!!! Úúúúú!!!) A modulban kötelező címzési módot és memória modellt megadni az OpMemoryModel utasítással. Pl. a GLSL más memóriamodellt használ, mint az OpenCL (és a SPIR-V mindkettőt támogatja, így a vulkán tulajdonképpen az OpenCL utódja is). Az annotációkat nem részletezem, ez ugyanaz, mint GLSL-ben a layout. Bizonyos utasításoknak van eredménye, amire később hivatkozni lehet (%eredmény = utasítás). A modul mindig úgynevezett SSA alakban van (static single assignment), azaz minden eredményt pontosan egy utasítás állít elő. Vigyázat, ez a szintaxis része, semmi köze nincs az utasítások tényleges eredményéhez! Vegyük például az alábbi zanzásított kódot:
Ez tehát közel sem jelenti azt, hogy temporáris változó jön létre! Furcsának tűnhet, de az OpVariable utasítás egyben definíció (azaz memória foglalódik), viszont pointert ad vissza. A második paramétere a storage class, ami teljesen hasonló, mint GLSL-ben; persze itt mindenre meg kell mondani. Magával a SPIR-V-vel nem foglalkoznék tovább, mert nehezen kezelhető és hosszabb kódokat eredményez, mint mondjuk a régi HLSL assembly. A továbbiakban GLSL-t fogok használni, glslang-al fordítva (ami azóta HLSL-t is tud). Részletekért lásd a vonatkozó GLSL specifikációt. Egy megemlítendő újdonság (az eddigiek mellett) az ún. specialization constant, ami a modul létrehozásakor megadható konstans adat, tehát a #if egy elegánsabb formája. Vulkán oldalon ez egy VkSpecializationInfo struktúra kitöltését jelenti a modul létrehozásakor, shader oldalon pedig: CODE
layout (constant_id = 7) const int sampleCount = 1;
void main()
{
vec4 blursamples[sampleCount];
}
A továbbiakban ez úgy viselkedik, mint egy szokványos konstans kifejezés és ezt a tulajdonságot az alapműveletek (de pl. a vektorrá konvertálás is) megtartják. Egy izgalmas dolog, hogy akár egy beépített változó is újradeklarálható így, például specializálni lehet (akár részlegesen) a workgroup méretét: CODE
layout (local_size_x = 16, local_size_y = 16) in;
layout (local_size_x_id = 3) in;
Így a workgroup y és z mérete rögzített, az x méret viszont megadható később is, fordításkor. Az atomic counter fogalom kikerült, helyette közvetlenül lehet atomi utasításokkal módosítani a (akár globális) memóriát (pl. imageAtomicIncrement). Tehát ami eddig atomic_uint volt, az most simán uint, egyébként minden ugyanúgy működik. Ez talán a legnehezebb része a vulkánnak, de ha egyszer megértetted, akkor már könnyebb a továbbhaladás. A rövid és érthető megfogalmazás érdekében forduljunk az Erőhöz:
Elég vad gondolat, hogy megválunk a glBindXXXX függvényektől, de mint említettem a korábbi API-k vért izzadtak ilyen esetekben, akár a shader-t is implicit újrafordították (de egy rossz driver predikció is micro stuttering formájában jelentkezett)! Ezt elkerülendő az összes (nem a pipeline-ból jövő) adat tulajdonságát meg kell mondani előre. Egy descriptor set összefoglalja azon (kívülről jövő) adatokat, amiket egy shader használ. Ezek lehetnek:
Fontos különbség akár OpenGL, akár Metal-hoz képest, hogy a binding point-ok a teljes (shader) programban szekvenciálisak, tehát ha a vertex shader már foglalja a 0-s binding point-ot, akkor a fragment shader azt már nem használhatja (hacsaknem pontosan ugyanaz a struktúra). A vulkán oldaláról nézve ezen információkat a descriptor set layout írja le, ami összefoglalja az adatok helyét, illetve tulajdonságait (de nem a konkrét adatokat!), úgy mint:
CODE
VkDescriptorSetLayout descsetlayout = 0;
VkDescriptorPool descriptorpool = 0;
VkDescriptorSet descriptorset1 = 0; // később lesz több
CODE
VkDescriptorSetLayoutCreateInfo descsetlayoutinfo = {};
VkDescriptorSetLayoutBinding bindings[2];
// két descriptor van
bindings[0].descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
bindings[0].descriptorCount = 1;
bindings[0].binding = 0;
bindings[0].stageFlags = VK_SHADER_STAGE_VERTEX_BIT;
bindings[0].pImmutableSamplers = NULL;
bindings[1].descriptorType = VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER;
bindings[1].descriptorCount = 1;
bindings[1].binding = 1;
bindings[1].stageFlags = VK_SHADER_STAGE_FRAGMENT_BIT;
bindings[1].pImmutableSamplers = NULL;
// descriptor set layout
descsetlayoutinfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO;
descsetlayoutinfo.pNext = NULL;
descsetlayoutinfo.bindingCount = ARRAY_SIZE(bindings);
descsetlayoutinfo.pBindings = bindings;
vkCreateDescriptorSetLayout(device, &descsetlayoutinfo, 0, &descsetlayout);
Felmerül az a kérdés, hogy mit kell akkor csinálni, amikor a descriptor set layout "lyukas"; azaz nem mindegyik binding-et akarod használni. A válasz szerencsére rövid: ne csinálj ilyet. Ha mégis szeretnéd és a validációs réteg átengedi, akkor a lyukakban a binding-et add meg, de a descriptorCount-ot állítsd 0-ra. Következzen a descriptor pool: CODE
VkDescriptorPoolCreateInfo descpoolinfo = {};
VkDescriptorPoolSize poolsizes[2];
// kétféle típust használ a shader, mindkettőből 1-1 descriptor-t
poolsizes[0].type = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
poolsizes[0].descriptorCount = 1;
poolsizes[1].type = VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER;
poolsizes[1].descriptorCount = 1;
// descriptor pool
descpoolinfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_POOL_CREATE_INFO;
descpoolinfo.pNext = NULL;
descpoolinfo.maxSets = ...; // amennyi váltást akarsz
descpoolinfo.poolSizeCount = ARRAY_SIZE(poolsizes);
descpoolinfo.pPoolSizes = poolsizes;
vkCreateDescriptorPool(device, &descpoolinfo, NULL, &descriptorpool);
Itt érdemes megjegyezni, hogy a maxSets és a pPoolSizes mezők között nincs semmiféle kapcsolat: ∑ pPoolSizesi darab descriptor-t lehet szétosztani maxSets darab set között. Foglaljunk le most már akkor valahány (most mondjuk 1) set-et: CODE
VkDescriptorSetAllocateInfo descsetallocinfo = {};
descsetallocinfo.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO;
descsetallocinfo.pNext = NULL;
descsetallocinfo.descriptorPool = descriptorpool;
descsetallocinfo.descriptorSetCount = 1;
descsetallocinfo.pSetLayouts = descsetlayouts;
vkAllocateDescriptorSets(device, &descsetallocinfo, &descriptorset1);
Vegyük észre, hogy sehol nem mondtam meg, hogy a shader hány descriptor set-et használ (bár lerögzítettem, hogy most 1-et fog). Azért, mert az nem itt dől el, hanem majd a vkCmdBindDescriptorSets() hívásban. Na de nem vagyunk még készen, mert eddig csak annyit mondtunk meg, hogy hogyan néz ki a set, de most meg kéne mondani a konkrét adatokat is: CODE
VkWriteDescriptorSet descsetwrites[2];
descsetwrites[0].sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET;
descsetwrites[0].pNext = NULL;
descsetwrites[0].dstSet = descriptorset1;
descsetwrites[0].descriptorCount = 1;
descsetwrites[0].descriptorType = VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER;
descsetwrites[0].dstArrayElement = 0;
descsetwrites[0].dstBinding = 0;
descsetwrites[0].pBufferInfo = ...;
descsetwrites[0].pImageInfo = NULL;
descsetwrites[0].pTexelBufferView = NULL;
// TODO: descsetwrites[1] hasonló (pImageInfo)
vkUpdateDescriptorSets(device, 2, descsetwrites, 0, NULL);
A szabvány itt egy kicsit szórakozott, ugyanis azt mondja, hogy ha a descriptorCount több, mint amennyit egyébként írhatna, akkor a következő binding-ben fogja folytatni. Soha az életben nem jössz rá, hogy hol rontottad el :) Ez a függvény nem hívható akármikor (pl. render pass-ban), szóval arra hajt az API, hogy a set-eket foglald le előre. A Khronos azonban megemlíti lehetőségként, hogy implementálsz egy saját descriptor set cache-t, amivel render időben is létre lehet ezeket hozni. A descriptor set layout legyártását erősen segíti a shader reflection, pontosabban a SPIR-V Cross. Ennek segítségével az is megoldható, hogy fordítási időben validáld a shader-eket, de C++ kódot is generál, amivel létrehozhatod a descriptor set-eket! Egyetlen feladat van még, a vkCmdBindDescriptorSets() meghívása. Ehhez viszont előbb meg kell ismernünk a graphics pipeline-t. Nem egy bonyolult fogalom, de nagyon sok részből áll, ezért célszerű elfedni egy wrapper osztállyal. A régi API-kkal és a metállal szemben csak nagyon kis részét lehet rajzolás közben módosítani (dynamic state), amit valószínűleg a Khronos is cikinek érzett, ezért használható egy ún. pipeline cache objektum, amit akár a merevlemezre is ki lehet menteni, így a programnak nem kell minden induláskor legyártania az ezerféle pipeline-ját.
A történet úgy kezdődik, hogy pipeline layout, ami tulajdonképpen csak a descriptor set layout-okat fogja össze (illetve még a push constant range-eket is, de azokról majd később). Ezután létrehozható a pipeline objektum, minden fent felsorolt állapotot teljesen megadva. A dynamic state-ben fel kell sorolni azokat a dolgokat, amiket nem itt szeretnél beállítani, hanem (mily meglepő) dinamikusan. Ezek közül sajnos nincs sok:
Mint mondtam, a graphics pipeline egy adott render pass-hoz kötődik, ami érthető is például a color blend miatt (ami attachment-enként különbözhet), de konkrétan is meg kell adni a VkGraphicsPipelineCreateInfo-ban. De akkor most már rajzolhatnánk valamit (feltételezve, hogy minden szükséges dolgot megcsináltatok): CODE
VkCommandBuffer commandbuffer = ...; // rajzolós cmdbuff
VkRenderPass renderpass = ...;
VkDescriptorSet descriptorset1 = ...;
VkPipeline pipeline = ...; // viewport/scissor dinamikus
VkPipelineLayout pipelinelayout = ...;
VkBuffer vertexbuffer = ...;
VkBuffer indexbuffer = ...;
CODE
VkRenderPassBeginInfo passbegininfo = { ... };
// ...
vkCmdBeginRenderPass(commandbuffer, &passbegininfo, VK_SUBPASS_CONTENTS_INLINE);
{
vkCmdBindPipeline(commandbuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipeline);
vkCmdSetViewport(commandbuffer, 0, 1, ...);
vkCmdSetScissor(commandbuffer, 0, 1, ...);
vkCmdBindDescriptorSets(
commandbuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipelinelayout,
0, 1, &descriptorset1, 0, NULL);
const VkDeviceSize offsets[1] = { 0 };
vkCmdBindVertexBuffers(commandbuffer, 0, 1, &vertexbuffer, offsets);
vkCmdBindIndexBuffer(commandbuffer, indexbuffer, 0, VK_INDEX_TYPE_UINT16);
// egy függvény mind felett
vkCmdDrawIndexed(commandbuffer, 36, 1, 0, 0, 0);
}
vkCmdEndRenderPass(commandbuffer);
Vajon miért lehet több viewport-ot (illetve ugyanannyi scissor rect-et) megadni? A válasz az, hogy a geometry shader megadhatja, hogy melyik viewport-ba szeretné kitolni a primitíveit. Ez tehát azt jelenti, hogy rajzolhatunk egyszerre több viewport-ba (mint ahogy annak idején egyszerre rajzoltunk egy cube map mind a hat oldalába). Vegyük észre, hogy az objektum típusa VkPipeline, mintha semmi köze nem lenne a grafikához. Valóban nincs köze, merthogy a compute pipeline is ugyanilyen objektum, szerencsére kevesebb járulékos adattal. Egy további hasznos fogalom a pipeline derivative, azaz egy már létező pipeline-ból származtatott "gyerek" pipeline, ami persze sokban hasonlít a szülőjére, így a létrehozása hatékonyabb. Az alapokkal gyakorlatilag készen vagyunk, egy dolog van még hátra: a képernyőre prezentálás. Ezt most nem írom le, mert a frame queueing kapcsán úgyis előjön. Említettem, hogy a command buffer-ek előre legyárthatóak, így a rajzolás konkrétan nulla driver overhead lehet. Az nVidia-nak van ez a threaded CAD scene nevű példaprogramja, ami pont ezt teszi, de gondoljunk bele néhány dologba:
A feladat az, hogy van egy tetszőleges poligonszámú elemekből álló jelenet, melyet szeretnénk minél gyorsabban megjeleníteni. A megvalósításhoz az Imagination egyik cikkét vettem alapul, ami a következőt mondja: a jelenetre alkalmazzunk valamilyen térpartícionálást (akár octree), minden levélbe valahány darab elemet rakva (az lesz egy batch). Ahogy mozog a kamera, minden újonnan bekerülő batch-hez generáljunk le egy másodlagos command buffer-t, a kikerülőket pedig töröljük. Nézzünk egy ábrát: 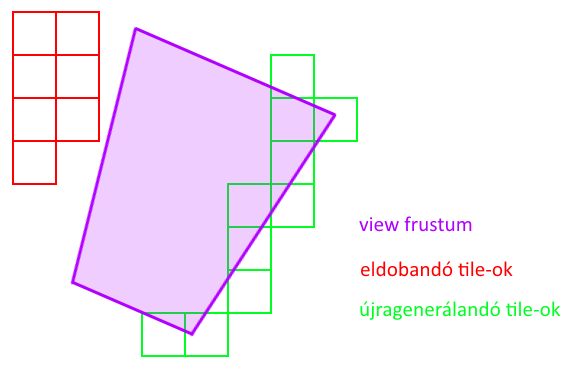
Ezen megoldással egyrészt elkerülhető, hogy a command buffer pool elszálljon memóriahasználatban, másrészt amíg egy batch a frustum-on belül van, addig nulla driver overhead-el leküldhető. Van azonban néhány rossz hír is a másodlagos command buffer-ekkel kapcsolatban:
(megj.: akkor miért nem használunk elsődleges command buffereket? Lehetne...de a kártya kevésbé fogja szeretni mint egy darab vkCmdExecuteCommands() hívást...) CODE
void DrawBatch::Regenerate(VkRenderPass renderpass, uint32_t currentimage)
{
VkCommandBufferBeginInfo begininfo = {};
VkCommandBufferInheritanceInfo inheritanceinfo = {};
inheritanceinfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_INHERITANCE_INFO;
inheritanceinfo.pNext = NULL;
inheritanceinfo.renderPass = renderpass;
inheritanceinfo.subpass = 0;
inheritanceinfo.framebuffer = framebuffers[currentimage];
begininfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO;
begininfo.pNext = NULL;
begininfo.flags = VK_COMMAND_BUFFER_USAGE_RENDER_PASS_CONTINUE_BIT;
begininfo.pInheritanceInfo = &inheritanceinfo;
vkBeginCommandBuffer(commandbuffers[currentimage], &begininfo);
{
// TODO: rajzolás
}
vkEndCommandBuffer(commandbuffers[currentimage]);
}
Nem fért ki, de ha frame queueing-ot is használsz, akkor a VK_COMMAND_BUFFER_USAGE_SIMULTANEOUS_USE_BIT flaget is add meg. Azzal nem foglalkozom most, hogy egy objektum ne legyen redundánsan bekódolva, megnézitek a kódban. Mint mondtam, ezt a regenerálást akkor kell meghívni, amikor egy új batch láthatóvá válik. Amiből persze esetenként elég sok lehet, tehát máris adódik egy gyorsítási lehetőség: osszuk szét több szál között! Ehhez szintén nem írok kódot, mindenki elhiszi. Na de mennyit gyorsultunk? Nos az általam írt program konkrétan lassabb vulkánnal, mint OpenGL-el (de eddig csak a GTX 650-en próbáltam ki, amiről megbeszéltük, hogy csal). Azt még el tudnám fogadni, hogy nem gyorsabb, hiszen a cikk elején említett driver limit nem igaz rá. Azért nem jelentősen lassabb a vulkán (~93 fps, míg az OpenGL ~110 fps), és ki lehetne deríteni, hogy pontosan hol akad el, ugyanis vulkánban (is) lehet GPU időt mérni query pool-okkal. Az előző bekezdés kapcsán felmerül még néhány kérdés (merthogy a command buffer-t előre legeneráltuk), nevezetesen, hogy hogy a búbánatba váltsunk uniform-okat (pl. material vagy world matrix). Bár fel vagyunk vértezve descriptor set-ekkel, ennél van egyszerűbb (sőt gyorsabb) megoldás. Vulkánban háromféle uniform típus van:
A megoldásom a következő: a material-okat bepakolom egy dynamic uniform buffer-be, a world mátrixot pedig (mivel adott elemhez kötődik) push constant-ként küldöm le. Ki kell egészíteni tehát a pipeline layout-ot és a shader-t:
Felhívnám a figyelmet, hogy shader oldalon minden ilyen változó egy struktúrában (std430 packing) kell legyen, program oldalon viszont a push constant range-ek ezekre egyesével kell vonatkozzanak. Ezek után rajzoláskor (feltételezve, hogy a material-okat megcsináltátok): CODE
vkCmdPushConstants(commandbuffer, pipelinelayout, VK_SHADER_STAGE_VERTEX_BIT, 0, 64, world);
vkCmdBindDescriptorSets(
commandbuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipelinelayout,
0, 1, descriptorset1, 1, &materialoffset);
Ezeket egyébként is gyakran kell használni, mert a vkCmdUpdateBuffer() nem hívható render pass-on belül. Bár minden lényeges dolgot leírtam a témáról, azért nem árt ha a gyakorlatban is látjuk hogyan működik (ezzel is elősegítve a megértést). Példának a Sponza nevű modellt használom (Sponza palota, Horvátország), amiben elég sok textúra van, tehát descriptor set-et kell váltani az egyes részek rajzolása előtt.
CODE
VulkanGraphicsPipeline* pipeline = ...; // minden hozzátartozó dologgal
VulkanBasicMesh* model = ...;
VulkanImage* supplytexture = ...; // helyettesítő textúra
VulkanBuffer* uniforms = ...;
CODE
// 0. group/layout
pipeline->SetDescriptorSetLayoutBufferBinding(
0, VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER, VK_SHADER_STAGE_VERTEX_BIT);
pipeline->SetDescriptorSetLayoutImageBinding(
1, VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER, VK_SHADER_STAGE_FRAGMENT_BIT);
// allokál és új group-ot kezd
pipeline->AllocateDescriptorSets(model->GetNumSubsets());
// TODO: további group-ok (most nem kell)
for( uint32_t i = 0; i < model->GetNumSubsets(); ++i ) {
VulkanMaterial& material = model->GetMaterial(i);
if( !material.Texture )
material.Texture = supplytexture;
pipeline->SetDescriptorSetGroupBufferInfo(0, 0, uniforms->GetBufferInfo());
pipeline->SetDescriptorSetGroupImageInfo(0, 1, material.Texture->GetImageInfo());
// beleírja az aktuálisan beállított adatokat
pipeline->UpdateDescriptorSet(0, i);
}
assert(pipeline->Assemble(renderpass));
Bár a szabvány lekezeli azokat az eseteket, amikor nincs beállítva textúra, a sampler-t mindenképpen meg kell adni (nem javaslom, hogy üresen hagyd a descriptor-t...). Ezek után rajzoláskor már könnyű dolgunk van, hiszen csak be kell állítani a material-hoz tartozó descriptor set-et. Természetesen felmerül a kérdés, hogy mennyire hatékony dolog descriptor set-et váltani, de a válasz már a felépítésből is adódik: minimalizálni kell a váltásokat. Ahogy régen a rajzolások csoportokba voltak szedve shader, material, textúra, illetve trafó szerint, úgy kell most megszervezni a set-eket a shader-ben: CODE
layout (set = 0, binding = 0) uniform GlobalData { ... } globals;
layout (set = 1, binding = 0) uniform MaterialData { ... } material;
layout (set = 2, binding = 0) uniform sampler2D texture;
layout (push_constant) uniform TransformData { ... } transform;
Ezt az nVidia és a Khronos javasolja, az AMD viszont mást mond: csak egy darab set legyen a shader-ben, tömbösítve. A konkrét használandó uniform-ot mondja meg egy push constant, ami ezt a tömböt címzi. Így nem kell rajzolásonként descriptor set-et váltani (One Set Design). Megint kilyukadtunk tehát a hardverfüggőségnél... A cikkhez írt deferred renderer kapcsán igyekeztem minél jobban kihasználni a vulkán lehetőségeit, így a render subpass-okat is. A renderer lépései:
A következő amit részletezni kell az a render pass attachment-ek leírása (melyekből ezek szerint 5 darab van). Gondoljuk végig mi is fog történni a render pass elkezdésekor (a paraméterek sorrendben: load action, store action, initial layout):
CODE
uint32_t preserveattachments[1] = { 0 }; // nehogy kidobja!
color1reference.attachment = 1;
color1reference.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
forwardreferences[0].attachment = 2;
forwardreferences[0].layout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
forwardreferences[1].attachment = 3;
forwardreferences[1].layout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
subpasses[0].inputAttachmentCount = 2;
subpasses[0].pInputAttachments = forwardreferences;
subpasses[0].colorAttachmentCount = 1;
subpasses[0].pColorAttachments = &color1reference;
subpasses[0].preserveAttachmentCount = 1;
subpasses[0].pPreserveAttachments = preserveattachments;
color0reference.attachment = 0;
color0reference.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
tonemapreference.attachment = 1;
tonemapreference.layout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
depthreference.attachment = 4;
depthreference.layout = VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL;
subpasses[1].inputAttachmentCount = 1;
subpasses[1].pInputAttachments = &tonemapreference;
subpasses[1].colorAttachmentCount = 1;
subpasses[1].pColorAttachments = &color0reference;
subpasses[1].pDepthStencilAttachment = &depthreference;
Tehát mivel más layout-ban kell majd használnom az 1-es attachment-et a két subpass-ban, ezért két külön attachment reference-et kell megadni. Még fontosabb a subpass dependency megadása: CODE
dependency.srcSubpass = 0;
dependency.srcAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstSubpass = 1;
dependency.dstAccessMask = VK_ACCESS_INPUT_ATTACHMENT_READ_BIT;
dependency.dstStageMask = VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT;
Ugye körvonalazódik most már, hogy ezen információkból a driver pontosan ki tudja találni a szükséges barrier-eket! De jöjjön a leglényegesebb dolog, ami abszolút nem nyilvánvaló senkinek: az összes attachment-et le kell törölni valamilyen színnel (azokat is, amikre LOAD-ot mondtam!): CODE
VkClearValue clearcolors[5] = { ... };
passbegininfo.clearValueCount = VK_ARRAY_SIZE(clearcolors);
passbegininfo.pClearValues = clearcolors;
vkCmdBeginRenderPass(commandbuffer, &passbegininfo, VK_SUBPASS_CONTENTS_INLINE);
Ez tehát kötelező, érdekes módon a blend state-eket viszont csak color attachment-ekre kell megmondani (de azért ne tessék elfelejteni; a gbuffer pass-hoz szükséges!). Ha ezeket mind megcsináltuk, akkor nagy gond már nem lehet...de mint említettem ha mégis gond van, akkor lehetetlen kideríteni, hogy mit hagytál ki (reménykedjünk, hogy okosítják a validációs rétegeket...). Mivel implementációs szempontból nem foglalkozik vele senki, kénytelen voltan saját kútfőből kitalálni valamit (a Metal megközelítését véve alapul).
Az ún. presentation engine-ről még nem írtam szinte semmit (VK_KHR_swapchain), úgyhogy előbb azt mutatnám be. Ez az ún. Window System Integration (WSI) része, ami extension-ök halmazaként jelenik meg. Maga a WSI elég bonyolult, úgyhogy nem foglalkozom vele részletesen.
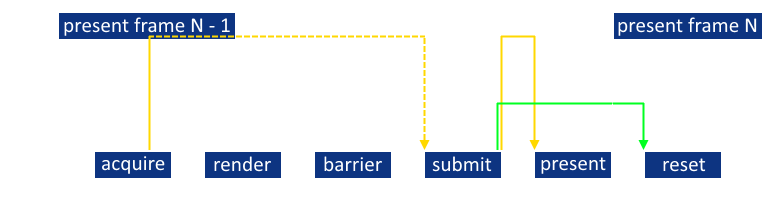
Mivel ezek tisztán szemaforokkal megoldhatóak a kérdés arra redukálódik, hogy mikor blokkoltassuk a CPU-t. Ahhoz, hogy a hardver ki tudja használni a deep pipelining képességeit 2-3 frame-et célszerű leküldeni neki, mielőtt elkezdenénk várakozni (az nVidia 2-t javasol). A megoldás a következő: frame-enként két szemafor (acquire/present), egy command buffer és egy fence (hogy tudjuk mikor lehet resetelni a command buffer-t). Egyes irodalmak frame-enkénti külön command buffer pool-t is javasolnak (fragmentáció elkerüléséhez). CODE
VkCommandBuffer commandbuffers[3];
VkSemaphore acquiresemas[3];
VkSemaphore presentsemas[3];
VkFence fences[3];
uint32_t currentframe = 0;
uint32_t currentdrawable = 0;
uint32_t buffersinflight = 0;
CODE
vkAcquireNextImageKHR(
device, swapchain, UINT64_MAX, acquiresemas[currentframe], NULL, ¤tdrawable);
// TODO: rajzolás + pre-present barrier
VkSubmitInfo submitinfo = {};
VkPresentInfoKHR presentinfo = {};
uint32_t nextframe = (currentframe + 1) % 3;
submitinfo.waitSemaphoreCount = 1;
submitinfo.pWaitSemaphores = &acquiresemas[currentframe];
submitinfo.commandBufferCount = 1;
submitinfo.pCommandBuffers = &commandbuffers[currentframe];
submitinfo.signalSemaphoreCount = 1;
submitinfo.pSignalSemaphores = &presentsemas[currentframe];
vkQueueSubmit(graphicsqueue, 1, &submitinfo, fences[currentframe]);
presentinfo.pImageIndices = ¤tdrawable;
presentinfo.waitSemaphoreCount = 1;
presentinfo.pWaitSemaphores = &presentsemas[currentframe];
vkQueuePresentKHR(graphicsqueue, &presentinfo);
++buffersinflight;
if( buffersinflight == 3 ) {
vkWaitForFences(device, 1, &fences[nextframe], VK_TRUE, 100000000);
vkResetFences(device, 1, &fences[nextframe]);
vkResetCommandBuffer(commandbuffers[nextframe], 0);
--buffersinflight;
}
currentframe = nextframe;
Szemfülesebb programozóknak feltűnhet, hogy nem tripláztam meg az uniform buffer-eket, mint metálban. Ezt azért mertem (nem) megtenni, mert a vkCmdUpdateBuffer() a megkapott adatot belemásolja a command buffer-be, így tulajdonképpen implicit elvégzi nekem (bár az átfedésekkel még elronthatja, ennek eddig nem láttam jelét). De természetesen úgy biztonságos, ha megcsinálod. A frame queueing-ra adhatóak alternatív megoldások, mert a vkWaitForFences() tud egyszerre több fence-re is várakozni (all/any jelleggel), de azt is meg lehet neki mondani, hogy ne várakozzon (hanem majd én lekérdezem az állapotát). Az acquire szintén történhet nem-blokkoló módon. Ezek mind abban segítenek, hogy a CPU és a GPU is minél több munkát tudjon elvégezni. Ha az applikáció főleg a CPU-n dolgozik, akkor érdemesebb nem-blokkoló megoldásokban gondolkodni. Az első keményebb dolog amit meg kell írnod ha vulkánozni szeretnél az egy memória szuballokátor (merthogy elmondtam, hogy 4096 a foglalási limit). Azt is elmondtam, hogy egy hardverfüggő érték befolyásolja, hogy buffer után milyen címre lehet image-et foglalni. Belépőszintű megoldásként azt választottam, hogy az allokátor 64 MB-os chunk-okban foglalja a memóriát, aszerint hogy:
A következő kritikus optimalizáció a barrier batching, az ugyanis rendkívül költséges művelet (üríti a cache-t). Amikor csak lehet szedd össze a barrier-eket egyetlen hívásba. Ehhez én egy VulkanPipelineBarrierBatch nevű osztályt csináltam és az alábbi módon használható: CODE
VulkanPipelineBarrierBatch barrier(
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT);
{
barrier.ImageLayoutTransfer(
swapchainimages[currentimage],
0, VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT,
VK_IMAGE_ASPECT_COLOR_BIT,
VK_IMAGE_LAYOUT_UNDEFINED, VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL);
barrier.ImageLayoutTransfer(
depthbuffer->GetImage(),
0, VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT,
VK_IMAGE_ASPECT_DEPTH_BIT|VK_IMAGE_ASPECT_STENCIL_BIT,
VK_IMAGE_LAYOUT_UNDEFINED, VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL);
}
barrier.Enlist(commandbuffer);
Ugye emlékszünk még, hogy mit mondtam a VK_IMAGE_LAYOUT_UNDEFINED-ről? Itt szándékosan van az megadva, mert valóban nem érdekel az adat. Bufferekhez a BufferAccessBarrier() metódus használható. A batch gyűjtögeti az adatokat, majd az Enlist()-ben illeszti be a konkrét barrier-t. Végül megemlíteném az indirect draw/dispatch hívásokat, amik bár OpenGL-ben is léteznek eddig nem nagyon foglalkoztam velük. A hívás azért indirekt, mert nem közvetlenül adod meg a paramétereit, hanem több paraméter csomagot adsz meg egy bufferben. Arra használható, hogy az egy bufferbe szuballokált objektumaidat egyetlen hívással (akár többször) rajzolhasd ki (mint egy batchelt instancing). CODE
// staging-et lekezeli
VulkanBuffer* indirectdata = VulkanBuffer::Create(
VK_BUFFER_USAGE_INDIRECT_BUFFER_BIT, 3 * sizeof(VkDrawIndexedIndirectCommand),
VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT|VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT);
VkDrawIndexedIndirectCommand* commands =
(VkDrawIndexedIndirectCommand*)indirectdata->MapContents(0, 0);
// indexCount, instanceCount, firstIndex, vertexOffset, firstInstance
commands[0] = { 36, 5, 0, 0, 0 };
commands[1] = { 162, 3, 36, 24, 5 };
commands[2] = { 324, 7, 198, 76, 8 };
indirectdata->UnmapContents();
// feltöltés a videómemóriába
VkCommandBuffer copycmd = VulkanCreateTempCommandBuffer();
VulkanPipelineBarrierBatch barrier(
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT);
{
indirectdata->UploadToVRAM(copycmd);
barrier.BufferAccessBarrier(
indirectdata->GetBuffer(),
VK_ACCESS_TRANSFER_WRITE_BIT, VK_ACCESS_INDIRECT_COMMAND_READ_BIT);
}
VulkanSubmitTempCommandBuffer(copycmd, true);
CODE
vkCmdBindVertexBuffers(...);
vkCmdBindIndexBuffer(...);
vkCmdDrawIndexedIndirect(
commandbuffer, indirectdata, 0, 3, sizeof(VkDrawIndexedIndirectCommand));
A többszöri rajzoláshoz szükséges a multidrawindirect feature megléte, anélkül maximum egyszer rajzolhat (de akkor ekvivalens a vkCmdDrawIndexed()-del). Nyilván előfeltétel, hogy az objektumok egy buffer-ben legyenek, illetve a megfelelő adataik típusa megegyezzen. A vkCmdDispatchIndirect() teljesen hasonló, compute shader-ekhez. A cikk megjelenése után kaptam egy AMD kártyát és hát bizony az összes progim szanaszét szállt rajta. Ez a bekezdés a kb. egy hetes nyomozásomból leszűrt tanulságokat foglalja össze.
CODE
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.srcAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT|VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstSubpass = 0;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT|VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dependencyFlags = VK_DEPENDENCY_BY_REGION_BIT;
És itt látjuk az első használatát a VK_DEPENDENCY_BY_REGION_BIT-nek, ugyanis ha a végrehajtási függőség framebuffer stage-ekre vonatkozik, akkor ezt meg kell adni. Mégegyszer megemlítem, hogy nVidia kártyán ne fejlessz! Olyan hiba is volt a programomban, hogy a memória szuballokátor egymást átfedő címekre foglalt szinte mindent...magyarán folyamatosan felülvágták egymás tartalmát, a GTX 650-en viszont semmi probléma nem jött ebből. De ilyen hibát is elkövettem, hogy túlírtam egy index buffer-t és mégis jól jelent meg az objektum...
A legjobb debug eszközök nyilván a validációs rétegek, amiket ajánlott minden nap frissíteni és újrafordítani, mert nagyon gyakran frissülnek és új hibákat hoznak ki a programodban. Azt viszont nem nagyon írják le sehol, hogy hogyan kell őket beállítani. Windows-on az alábbi registry kulcsot kell kitölteni: HKEY_LOCAL_MACHINE/SOFTWARE/Khronos/Vulkan/ExplicitLayers. Minden réteghez fel kell venni egy 0 értékű DWORD-öt, névnek pedig add meg az adott réteg .json fájljának elérési útját.
A könnyebb tájékozódás érdekében a fontosabb fogalmak, összefoglalva:
És még sorolhatnám... de ezeket kell álmodból felébresztve kenni-vágni. Nem mondok olyat, hogy "ezt is túléltük", mert épphogy csak nekikezdtünk. Mostantól fognak csak jönni az újabbnál újabb GPU trükkök, a szabvány fejlődéséről nem is beszélve. Maga a vulkán szabvány is annyi lehetőséget ad, amivel könyveket lehetne megtölteni (és akkor vegyük hozzá, hogy nem is mindenkinek világos, hogy mi miért van). Foglaljuk össze a vulkán előnyeit:
A szabványt bújva vannak jó hírek, pl. visszakerült a triangle fan topológia és a user clip plane-ek (a CullDistance szemantika formájában) de persze ez is, mint minden hardverfüggő... Nem tudom mennyire jó hír, de a blend operation mellett meg lehet adni logical operation-t is (mint a stencil buffer-nél, de jóval több lehetőséggel). Kód a szokásos helyen, a deferred renderer-ről pedig videó. Lehet kezdeni új engine-t írni... Höfö:
Irodalomjegyzék https://www.khronos.org/registry/vulkan/specs/1.0-wsi_extensions/xhtml/vkspec.html - Vulkan specification (Khronos, 2016) https://www.khronos.org/registry/vulkan/specs/misc/GL_KHR_vulkan_glsl.txt - GL_KHR_Vulkan_glsl (Khronos, 2015) https://www.khronos.org/assets/.../10-Porting-to-Vulkan.pdf - Porting to Vulkan (Khronos, 2016) https://www.khronos.org/assets/.../4-Using-spir-v-with-spirv-cross.pdf - Using SPIR-V with SPIR-V Cross (Khronos, 2016) https://www.khronos.org/assets/.../Khronos-OpenGL-Efficiency-GDC-Mar14.pdf - OpenGL Efficiency: AZDO (Khronos, 2014) http://gpuopen.com/.../Most-common-mistakes-in-Vulkan-apps.pdf - Most Common Mistakes in Vulkan Apps (AMD, 2016) http://gpuopen.com/.../VulkanFastPaths.pdf - Vulkan Fast Paths (AMD, 2016) http://on-demand.gputechconf.com/siggraph/.../SIG1501-Piers-Daniell.pdf - Vulkan on nVidia GPUs (nVidia, 2015) https://developer.nvidia.com/vulkan-memory-management - Vulkan Memory Management (nVidia, 2016) https://developer.nvidia.com/vulkan-shader-resource-binding - Vulkan Shader Resource Binding (nVidia, 2016) https://imgtec.com/blog/gnomes-per-second-in-vulkan-and-opengl-es/ - Gnomes per Second (Imagination, 2015) |
