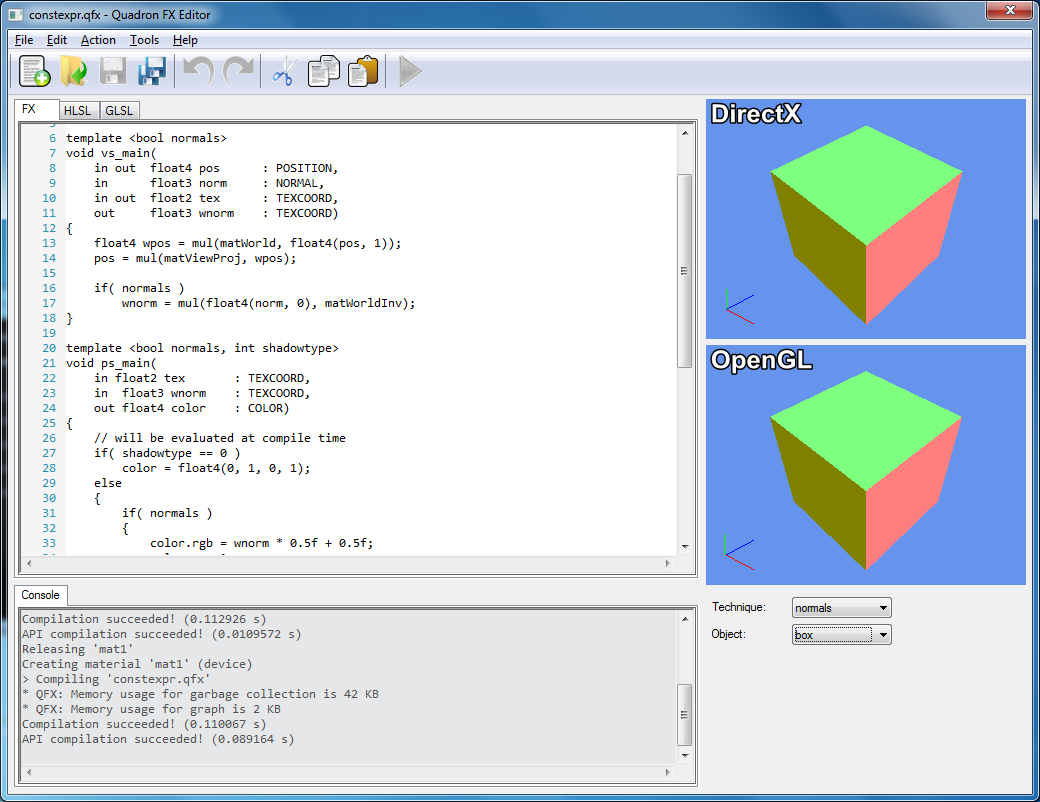
|
Bár eddig is implementációs részleteket osztottam meg, ez a cikk most konkrétan a Quadron VP egy részéről fog szólni, nevezetesen a shader fordítóról.
Bizonyos szempontból a scriptes tutoriálok folytatásának tekinthető, mert egy igen érdekes dolgot is meg fogok említeni: a template-ek fordítását.
CODE
foo<2>(3);
a fordító nem tudja eldönteni, hogy ez most függvényhívás template paraméterrel, vagy pedig aritmetikai kifejezés. Megoldási lehetőség nem sok van; vagy másik szimbólumot használsz, vagy másik parsert (a bison-nak van GLR opciója, de fordítási hibákat dobott, úgyhogy inkább hanyagoltam). Végül úgy oldottam fel, hogy a < elé egy @-ot kell írni.
Hülye-e vagy, séderben templét???
Állj, állj. Először is minden normális fordító tud ilyet valamilyen formában (pl. a HLSL-nek meg lehet adni a compile utasításban paramétereket), kivéve a GLSL-t.
Másrészt az egy sokkal cikibb kérdés, hogy egyáltalán miért használnak az enginek saját fordítót? Nos, a legjobb érv nyilván a platform/API függetlenség, de én mondok egy jobbat:
Világmegváltó vagy
Nem. De elvből kerülök minden third party libet. Másrészt tapasztaltam, hogy sok shader esetén mennyire kezelhetetlen négyféle különboző nyelven írt shadereket karbantartani.
Harmadrészt megvan minden tudásom ahhoz, hogy megoldjam ezt a problémát, akkor meg miért ne? - Mondjuk mert játékot kéne fejleszteni, gyökér...
Vegyük észre, hogy a konstans kifejezések fordítási idejű kiértékelése mellett a fordító a nem használt varying-okat is kidobta. Hasonlóan feltűnhet, hogy a textúra koordinátáknak nem adtam meg regisztert (jobb híján legyen ez későn kötés), ezt még a HLSL sem tudja (de annak oka van). Nyilván bizonyos szabályok érvényesülnek, ezekről majd később. A refaktoring célja tehát az volt, hogy ezt így meg lehessen csinálni.
Dö szolúsün
Először is, miért volt rossz a régi? Nem volt rossz, az akkori igényeknek tökéletesen megfelelt. A működése teljesen hasonló volt a scriptes tutoriálban ismertetett fordítóéhoz: parseolás közben előállította a megfelelő kódrészleteket,
majd a végén (technika deklaráció) összeollózta a konkrét shaderbe. Világos, hogy ezzel igen nehéz megoldani a fent említett példányosítást, hiszen lefordított kódban már nem sok információd van arról, hogy
mi is az tulajdonképpen. Bár azt lehet tudni, hogy mondjuk egy if_statement kódja az úgy kezdődik, hogy if, aztán egy feltétel, de ezzel már igen nagy kínlódás dolgozni. Más megoldás kell.
Innentől kezdve egy adott akció (pl. fordítás) a fa bejárását jelenti. Sőt, bejárás közben a programot úgymond ki is lehet értékelni, azaz megmondható, hogy egy változó használva van-e, illetve a konstans kifejezések azonnal kiértékelhetők. Ennek persze ára van: a fordítás az eddigi kettő helyett (előfordítás + fordítás) némileg több lépésből áll:
Egy érdekes kérdés, hogy mi történjen olyan (formális) függvényparaméterekkel, amik nincsenek használva. Mondhatnám azt, hogy legyen kidobva, de gondold meg, hogy mit történik, ha ezt írom le: foo(a = b);. Ilyenkor vagy meghagyom a függvényparamétert, vagy itt a hívás helyén az értékadást kiviszem a függvényhívás elé. Többek között erre van használva egy csúcsra az IsModifying() metódus, ami megmondja, hogy módosít-e bármit az a csúcs vagy alcsúcsai.
Egy UML ábra
Csak azért, hogy 10 cm-en belül két kép is megtörje a szöveg folyamatosságát. Ebből mindjárt látni lehet majd, hogy nem is érdemes tovább olvasnod a cikket, mert
úgysem érted. Pedig tudnátok mennyit kínlódtam ezzel az egy diagrammal...
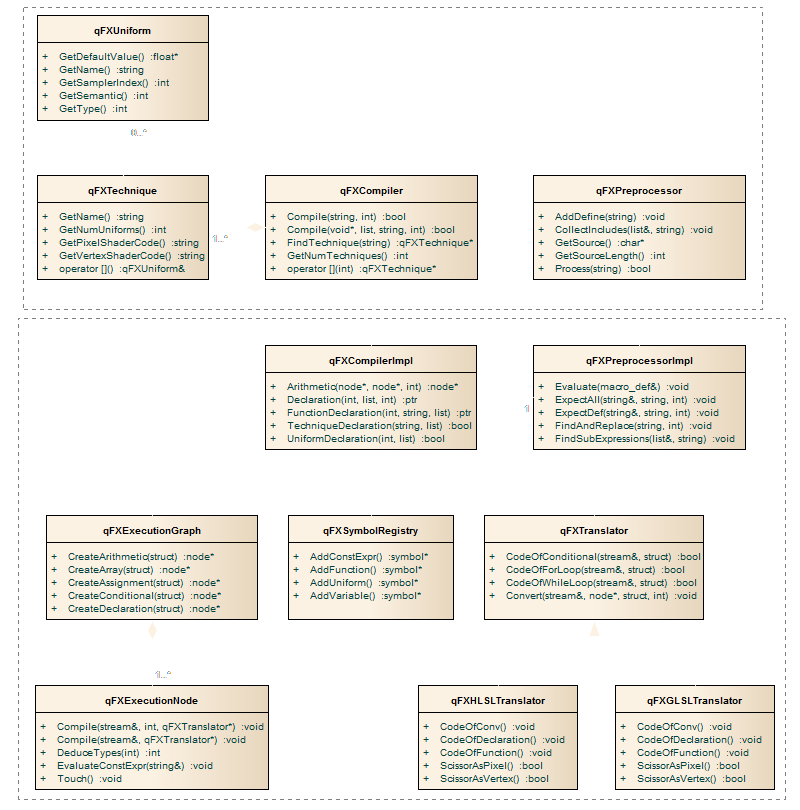
A symbolregistry kicsit megtévesztő állat, mert bár ez hoz létre minden szimbólumot, csak a parseolás alatt tárolja azokat (illetve a globális scope-ban levőket mindig). A szimbólumokat a szemétgyűjtő törli ki (nincs feltüntetve), illetve az execution node-ok használják őket. Az execution node-ból leszármazik egy rakat egyéb node típus (a fenti agyament ábrából lehet meríteni inspirációt), például qFXFunctionCall, qFXArrayInitializer, qFXArithmetic stb. Ezeknek célzott member változói mutatnak a további csúcsokra, például egy aritmetikai kifejezésben left, right. Bemásolom ide mondjuk az elágazást: CODE
struct qFXConditionalDesc
{
qFXExecutionNode* Condition;
execnodearray IfStats;
execnodearray ElseStats;
qFXConditionalDesc()
{
Condition = 0;
}
};
class qFXConditional : public qFXExecutionNode
{
public:
qFXConditionalDesc Desc;
// traversal methods
void Compile(std::stringstream& out, qFXTranslator* translator);
void Compile(std::stringstream& out, qFXTypeName target, qFXTranslator* translator);
void Touch();
// queries
bool IsModifying() const;
bool IsConstExpr() const;
// type deduction
qFXTypeName DeduceTypes(qFXTypeName hint) const;
};
Ez egy érdeket design pattern, talán a privát információ publikálásának lehetne hívni :) Nem dehogyis, ezek a struct-ok data transfer object-ek, hogy a létrehozás és későbbi feldolgozás egyszerűbb legyen. Magát a származtatott csúcsot ugyanis nem látja minden osztály (ezzel is elősegítve, hogy általános és transzparens legyen). Végül az execution graph az amiben a fordítás oroszlánrésze történik (fentebb említettem, hogy mik) egy translator segítségével. A translator az egyetlen olyan osztály, ahol egy konkrét shader nyelv elemei megmutatkoznak. Szekvenciadiagramot eszem ágában nincs rajzolni, de valahogy úgy történik a buli, hogy a compiler meghívja az előfordítót, majd elindítja a parsert, ami hívogatja a compiler megfelelő metódusait, végül eljut egy TechniqueDeclaration() hívásba. Ott aztán többször bejáródik a fa (ld. fent), speciel a végén még fordít is. A fa hívja tovább a translatort (amit megkap paraméterben), és visszaad egy stringet a friss, ropogós és crashelős GLSL shaderrel.
Típus dudaakció
Valójában nincs rá szükség, hiszen mondhatnám az alábbit: CODE
uniform sampler2D sampler0 : TEXUNIT0;
uniform samplerCUBE sampler0cube : TEXUNIT0;
Dehát ne legyünk igénytelenek, ha már ilyen szuper megoldást sikerült találni. Legyen simán sampler és a konkrét shader alapján döntse el a fordító, hogy mi a típusa. Később hasonlóan lehetne majd egyéb dolgokat is bevezetni (matrix, vector). Megjegyzem a HLSL fordító tudja ezeket, sőt. Na de, a probléma nem annyira trivi. Tekintsük például az alábbi kódot: CODE
uniform sampler typeless : TEXUNIT0;
float4 testfunc2D(in sampler samp, in float2 tex)
{
return tex2D(samp, tex);
}
void ps_2D(
in float2 tex : TEXCOORD0,
out float4 color : COLOR)
{
color = testfunc2D(typeless, tex);
}
Tovább lehetne bonyolítani, de a GLSL nem tud visszatérő értékként sampler-t, úgyhogy azt legalább megúsztam (persze lehetne inlineosítani, de na). A példában rögtön két szimbólumra is meg kell mondani, hogy mi a rák az: typeless és samp. A konkrét dedukció nyilván a tex2D-nél fog megtörténni, azzal samp letudható, na de hogy gyűrűzik az vissza a másikhoz? Nem olyan bonyolult a dolog. A bejárás most tart ott, hogy testfunc2D, ez egy függvényhívás típusú csúcs. Először dedukáljuk le a függvényt, ezzel megvan samp, mint formális paraméter típusa. A feladat dedukálni az aktuális paramétereket; adjuk be tippnek az előbb dedukált formális paraméter típusokat: CODE
qFXTypeName qFXFunctionCall::DeduceTypes(qFXTypeName hint) const
{
qFXSymbolDesc* sym;
qFXFunctionDesc* func = (qFXFunctionDesc*)Desc.Symbol;
const symbollist& formals = func->GetFormalParams();
symbollist::const_iterator it = formals.begin();
// first deduce called function
if( !func->IsBuiltIn() )
graph->DeduceTypes(func->GetName());
// then deduce args
for( size_t i = 0; i < Desc.Args.size(); ++i, ++it )
{
sym = (*it);
Desc.Args[i]->DeduceTypes(sym->GetType());
}
// and deduce return value
return graph->DeduceTypeForSymbol(Desc.Symbol, hint);
}
A tippet nem kötelező figyelembe venni, de ha használva van, az előbb-utóbb egy graph->DeduceTypeForSymbol(sym, hint) meghívását jelenti. Ebben van eldöntve, hogy lehet-e, illetve mire kell dedukálni. Ebben az esetben sampler2D fog bejönni tippnek és ennek nagyon fog örülni (a void-nak kevésbé szokott). Egy picit csalok, mert a visszatérő érték típusának ez nem feltétlenül elegendő. Hol lehet még dedukálni visszatérő értéket? Úgyvan, a return utasításban. Én ezt lusta módon a függvény dedukálásakor teszem meg (hiszen tudható, hogy egy utasítás return-e).
Későn kötő TEXCOORD
Egy kis kitérő: mire kell a szemantika? HLSL-ben nincs külön linkelés, hanem ebből tudja meg, hogy melyik vertex outputhoz melyik pixel input tartozik.
GLSL-ben ez név alapján megy.
Hasonlóan lehet eljárni COLOR-al is. Az ereje ennek nyilván abban rejlik, hogy ami nem kell az kioptimalizálódik, így amíg befér a 8 regiszterbe addig megy minden kőkori vackon is.
Implicit típuskonverzió
A konverzióknak többféle típusa lehet:
CODE
#define MAKE_TYPE(p, m, r, c) ((p)|(m)|(((c << 4) & 0xf0)|r))
enum qFXTypeName
{
...,
qTN_Float4 = MAKE_TYPE(qPT_Single, qMT_Vector, 1, 4),
...,
qTN_Float4x4 = MAKE_TYPE(qPT_Single, qMT_Matrix, 4, 4),
...
}
Így minden fellelhető típusnak könnyen megmondható a precíziója, hossza, stb. Ezután egy listába fel lehet venni, hogy mely típuspárok között lehetséges egyáltalán konverzió. Ami egy érdekesebb dolog az a függvénytúlterhelés. Ekkor ugyanis egy adott halmazból kell kiválasztani azt az elemet, amelyik a hívásnak a legmegfelelőbb. Ennek megoldásához egy költségfüggvényt definiáltam, ami két típus között megmondja a konverzió költségét. Két függvény távolsága a megfelelő paraméterek költségeinek súlyozott összege. A legjobb túlterhelés az, aminek a legkisebb a távolsága az aktuális paraméterektől. A költségfüggvény az alábbi szempontokat veszi figyelembe:
A konkrét konverzió hossz kasztolása esetén swizzle, precízió kasztolásakor pedig típuskonstruktor. Megjegyezném, hogy skalárt lehet vektorba kasztolni (value.xxxx).
Konstans kifejezések kiértékelése
Az előfordítóban a már említett shunting yard algoritmussal.
A fordítóban kicsit más a helyzet, mert ott konstans szimbólumokra és konstans változókra kell tudni elvégezni műveleteket, sőt konverziókat is figyelembe kell venni.
Én erre egy elég hatékony megoldást adtam a template metaprogramming segítségével.
Ennyit segítek: CODE
template <template <typename> class func>
void GeneralOperator(qFXTypeName target, qstring& val1, const qstring& val2)
{
// TODO:
}
typedef void (*operatorfunc)(qFXTypeName target, qstring& val1, const qstring& val2);
operatorfunc operators[] =
{
&GeneralOperator<std::plus>,
&GeneralOperator<std::minus>,
&GeneralOperator<std::multiplies>,
...
}
A teljes megoldás höfö >:) Vektorokat egyelőre nem tud.
Nagyon szemét gyűjtés
A scriptes tutoriálban taglaltam egy garbage collectort, eddig azt használtam itt is. Azonban rájöttem, hogy szar, mert a logaritmikus keresés lassú, másrészt egyszerűbben is meg lehet oldani.
Az engine-nek van régóta allocation trackere, ami még olyan ügyes is, hogy a fix memóriaterületét (amiben egy hashtáblát dugdos) még defragmentálja is, így addig működik amíg szeretne. Copy-paste.
Ettől sokan beájulnak, nekem viszont az aláírásom is template-el kezdődik (ha esetleg változna a nevem ugyebár...). Attól dobnátok hátast, ha megmondanám mit csinálok olyankor, amikor nincs default konstruktora a value_type-nak. Egy fontos dolog, hogy ARM processzorokon az ilyen előre allokált memóriaterületekben maszatolás veszélyes, mert ha egy pointer nincs 4 bájtra alignolva az vidám exception lesz (és csak release fordítással!).
#line
Miért is kell ez? Gondolj a #include-ra: ha az inkludált fájlban van hiba, akkor arra vonatkozóan kéne kiírni a hibaüzit. Hasonlóan a kommentekkel is gond van: az előfordító már kiszedi
azokat, így a lexerben a sorvégejel lekezelése nem lesz elég. Egy általánosan bevett módszer erre, hogy az előfordító teletűzdeli a kódot ilyen #line direktívákkal.
CODE
#line 15 "myshader.qfx"
Na de mikor kell ezeket beszúrni? Tipikusan oda ahol az előfordító átugrott valamit (pl. komment). A #include-ot célszerű egy rekurzív Process() hívással elintézni, így a behúzott fájlok sorszámai is 0-tól indulnak. Ami nem egyértelmű, hogy a beszúrt direktívákat hol érdemes feldolgozni. Némi kínlódás után egyértelműsödik, hogy a lexikális elemzőben. Na de hogyan? Máris mutatom: CODE
"#line"{WHITESPACE}+{INTEGER}{WHITESPACE}+"\""[^\"\n]+"\"" {
qstring str(yytext);
qstring lineno, fname;
size_t start, end;
// get line number
start = str.find_first_of("0123456789");
end = str.find_first_not_of("0123456789", start + 1);
lineno = str.substr(start, end - start + 1);
// get file name
...
QuadronFX::Log().SetFileInfo(fname, atoi(lineno.c_str()) - 1);
}
A lényeg az yytext globális, ugyanis ez mutat az illesztett stringre. Ez mindig egy nullával zárt tömb, szóval azt csinálsz vele amit akarsz. Nyilván elég megkeresni benne a sorszámot és a fájlnevet, amit aztán el lehet tárolni. Megjegyzendő, hogy a sorvégejel továbbra is ++-olja az aktuális sorszámot.
Metainfók az editornak
A HLSL és a CG megközelítése nekem nagyon nem tetszik, olvashatatlan lesz tőle a shader kód. Kiszedni pdig nagyon nehéz, mert az egész kódot végig kell nyálazni hozzá.
Én ezért a metainfót a technika deklarációba engedem csak rakni egy @valami blokkba. Ez a valami bármi lehet, de az editor értelemszerűen csak akkor fogja figyelembe
venni, ha @editor-t írtál.
CODE
@editor
{
mesh = screenquad;
textures[0] = render(reflect);
}
Ezt is a parser dolgozza fel (hiszen szintaktikus elem), viszont az editornak csak kulcs-érték párokat küld le (stringként), ami aztán értelmezi. A render utasítás a megadott technikával kirajzolja a jelenetet a bal oldalon megadott rendertargetbe. Így egyszerűen lehet akár postprocess láncokat is csinálni. Hasonlóan lehet merevlemezről is betölteni textúrát vagy mesh-t, Némi hiányossága még van, például a rendertarget formátumát nem lehet megmondani.
Summarum
A cikkben ismertettem néhány (új) implementációs részletet, amit scriptnyelvek írásánál fel lehet használni.
Néhány dolgot még meg kéne csinálni, pl. a kiforgatható ciklusokat kiforgatni. Ez egy picit bonyolultabb téma, de természetesen az eddigiek felhasználása szükséges.
Tisztán szemantikai alapon is meg lehet oldani, de vajon hogy mondod meg, hogy egy ciklusban mi a ciklusváltozó? Lehet, hogy nincs is, mégis véges lépés után terminál.
Valószínűleg sokkal egyszerűbb (kvázi) végrehajtani a kódot, és az alapján kiforgatni (a HLSL azt csinálja). Ez már egy következő szint, nekem is el kell rajta merengeni.
A fordítás láthatóan nem valami gyors, ezen még optimákolni kell (de van egy olyan érzésem, hogy a lexer/parser a lassú). Kipróbálható verzió... majd lesz, de még sok TODO van. Höfö:
|