|
A 21. század technológiai vívmányainak egyik jeles képviselőjén (melyet hívjunk most shader-nek) vérszemet kapva felmerült az igény arra, hogy a GPU-t ne csak rózsaszín pónilósimogató játékokra
használják, hanem tudományos berkekben régóta problémát jelentő algoritmusokat is átvigyenek oda. Ami annyira nem is volt egyszerű, hiszen 2001 környékéről beszélünk, amikor még épphogy assemblyben lehetett shadereket írni, sőt
a probléma megoldását egy más szemlélettel át kellett alakítani az akkori API-k számára emészthető formába (pont, vonal, háromszög).
A valódi cél viszont a GPGPU grafikában való felhasználása, ezért úgy döntöttem, hogy a lehető legújabb technológiáról írok cikket, ami a compute shader. A nevéből is kitalálható, hogy ez szorosan része a választott API-nak (jelen esetben OpenGL 4.3), így ilyen célra sokkal hatékonyabb. A másik oldalon DirectX 11-től érhető el (de korlátozottan DX10-es kártyán is fut). Zárójelben még annyit említenék meg, hogy így 2013 után valami bábeli zűrzavar kezd kialakulni a grafikai API-k körül, ugyanis sorra jelennek meg új, nagyrészt platformfüggő API-k (holott az igény pont az lenne, hogy csak egy legyen, de mindenhol). Néhány ezek közül: Mantle (AMD), DirectX 12 (Microsoft), Metal (Apple), OpenGL 5 (Khronos alkoholterápiás csoport). A közös ezekben az, hogy (egymásról másolva) egy sokkal hardverközelibb "élményt" nyújtanak, ami elég meglepő tekintve, hogy programozás területén eddig az absztrakció volt a menő (nesze neked ELTE bevprog...). Mindenesetre mindegyikben alapból benne van a compute shader valamilyen formában, ez tehát plusz egy indok arra, hogy foglalkozzak vele. Tartalomjegyzék
A GPU egy massively parallel architektúra, azaz a teljesítményét brutális párhuzamosítással éri el. A CPU és GPU közti különbséget legjobban ez a
videó szemlélteti: míg a CPU néhány magja szekvenciális feldolgozásra van optimalizálva, addig a GPU a több ezer magjával
a (masszívan) párhuzamos feldolgozásra épít.
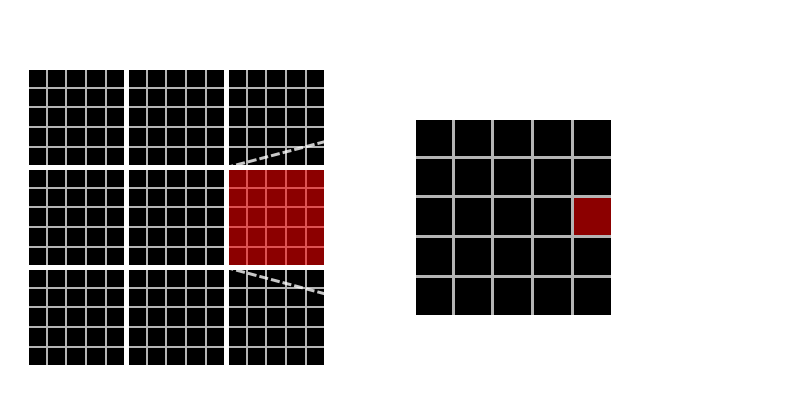
Egy compute unit több work group-ot is futtathat egyszerre, de egy work group-on belül egyszerre 32 thread fut egymás mellett (ez megint csak nVidia kártyákra igaz, AMD-n úgy tudom 64). Az egy compute unit-on való futás miatt az egy work group-on belüli work item-eknek van közös memóriája, melyet szinkronizációs utasításokkal lehet írni/olvasni. Természetesen globális memória is van, de azok már csak bufferként jelennek meg. Amit fontos még megemlíteni, hogy egy kernel milyen memóriákat tud használni:
A bevezetés után rátérnék arra, hogy OpenGL 4.3-ban hogyan mutatkozik meg ez a compute shaderes buli. Négy új extension van ami ehhez szorosan kapcsolódik:
Az első szembetűnő dolog a sok layout minősítő. Ezek többnyire hint-ek a drivernek (pl. sampler esetében megmondható a textúra formátuma). Végre meg lehet adni binding point-ot is (a.k.a. regiszter), így nem kell uniformként beállítani. A textúra létrehozását gondolom nem kell bemutatni, de látható hogy 128x128-as. A shadert is teljesen hasonlóan kell betölteni mint eddig, csak a glCreateShader(GL_COMPUTE_SHADER) hívásban különbözik a régitől. A programhoz csak ezt a compute shadert kell hozzáattacholni (és nem is lehet mást). A sakktábla mintában egy csempe egy workgroup. Azt, hogy éppen melyik csempében vagyok ki lehet számolni a beépített gl_GlobalInvocationID változóból. Minden második csempe színes lesz, a többi fekete. Megjegyezném, hogy valójában elég lenne workgrouponként egyszer kiszámolni, hiszen az első 32-es thread csoport lefutása után már pazarlás (később). A következő bekezdésekben példákon keresztül mutatom be részletesebben a használatot és a megvalósítható technikákat. Erősen ajánlott az OpenGL 4.4 és GLSL 4.3 specifikáció tanulmányozása, ugyanis minden ide vonatkozó dolog le van benne írva (még ha nehéz is megtalálni).
Ebbe a kategóriába tartozik minden olyan (megvilágítási) módszer ami a képernyőt csempékre osztva optimalizálja a fragmentekre ható fények számát.
Még a compute shader előtti időkben a deferred lighting legnagyobb előnye az volt, hogy sok fényforrást tudott kezelni, így játék szempontból az lett a meghatározó (és a forward rendering háttérbe szorult).
CODE
device.SetBlendMode(Additive);
foreach (Object o in objects)
{
foreach (Light l in lights)
o.DrawWithLight(l);
}
A forward+ annyiban javít ezen, hogy a fényekre vonatkozó (belső) ciklust átviszi shaderbe. Most mindenki akadékoskodik, hogy "dehát ezt eddig is meg lehetett volna csinálni". Persze, csak épp objektumonként mondjuk 1000 fényre ciklust futtatni shaderben elég gáz (hacsak nem diavetítés a cél). Az észrevétel az, hogy normális programozók esetében a sok fényforrás kvázi egyenletesen oszlik el a képernyőn, tehát az egy pixelre ható fények száma nagyságrendekkel kisebb, mint az összes fény száma. Tehát ha a képernyőt részekre osztom és mindegyik részre meg tudom mondani, hogy milyen fények hatnak oda, akkor hatalmas teljesítményjavulást lehet elérni. Először leírnám a renderer és a compute shader lépéseit (a Kibaszott Fontos Lépés ®-eket KFL-nek rövidítem):
 A feladat megcsinálni ezt compute shaderben, beleértve a láncolt listában való tárolást is. Aki tudja mi az az uniform buffer, annak ismerős lesz a shader storage buffer (SSBO) is,
merthogy teljesen hasonló, csak sokkal nagyobb lehet (legalább 16 MB-ig támogatnia kell a drivernek), illetve írható shaderből. DirectX 11-ben egy UAV-al ellátott buffer felel meg ennek (unordered access view).
A programban a következő bufferek vannak használva:
A feladat megcsinálni ezt compute shaderben, beleértve a láncolt listában való tárolást is. Aki tudja mi az az uniform buffer, annak ismerős lesz a shader storage buffer (SSBO) is,
merthogy teljesen hasonló, csak sokkal nagyobb lehet (legalább 16 MB-ig támogatnia kell a drivernek), illetve írható shaderből. DirectX 11-ben egy UAV-al ellátott buffer felel meg ennek (unordered access view).
A programban a következő bufferek vannak használva:
A használat viszont már egész más mint a "régi" bufferek esetében. GLSL oldalon a buffert egy interface block definiálja, a megfelelő minősítőkkel. Egy ilyen blokk tartalmazhat indefinit tömböt is (ez kb. megfelel egy pointernek):
Kezdeném azzal, hogy mi az az std140. Ez egy platformfüggetlen memory layout, amelyet a szabvány definiál (OpenGL spec 7.6.2.2): a struktúra tagjai alignolva lesznek a megadott szabályok szerint. Az std430 teljesen hasonló, viszont nem paddeli ki 16 bájtra az egyébként érvényes struktúrákat (pl. uvec2). Van egy másik ilyen layout (packed) ami arra szolgálna, hogy ne történjen paddelés, de az is csak nVidia kártyákon megy (mily meglepő) és egyébként platformfüggő, szóval ne használjátok. Én annyira óvatos vagyok ezzel, hogy a vec3 + float kombót se vállalom be, mert szerintem az AMD 32 bájtra paddelné ki... Az offseteket egyébként le lehet kérdezni OpenGL oldalon a glGetActiveUniform hívással (én ezt eddig nem tettem meg). Csak a szemléltetés kedvéért megmutatom hogyan lehet shared változókat használni a compute shaderben. Például egy adott tile-ra vonatkozó mélység ilyen shared változó: CODE
shared uint TileMinZ;
shared uint TileMaxZ;
layout(local_size_x = 16, local_size_y = 16) in;
void main()
{
if( gl_LocalInvocationIndex == 0 )
{
// kezdőérték, csak egyszer kell lefusson
TileMinZ = 0x7F7FFFFF;
TileMaxZ = 0;
}
barrier(); // szinkronizáció
vec2 tex = vec2(gl_GlobalInvocationID.xy) / screenSize;
float depth = texture(depthSampler, tex).r;
float linearz = (0.5 * matProj[3][2]) / (depth + 0.5 * matProj[2][2] - 0.5);
float minz = min(clipPlanes.y, linearz);
float maxz = max(clipPlanes.x, linearz);
if( minz <= maxz )
{
atomicMin(TileMinZ, floatBitsToUint(minz));
atomicMax(TileMaxZ, floatBitsToUint(maxz));
}
barrier(); // szinkronizáció
// ... folyt ...
}
A lényeg a barrier() hívás, ami addig blokkol amíg a work group-on belül minden thread el nem jutott arra a pontra. Ennek tudatában már világos a működés: minden thread atomi utasításokkal buherálja a két shared változót, majd amikor mindegyik elért a barrier-hez, a változókban ott van a helyes érték. Annyi szépséghiba van, hogy ezek az atomi utasítások csak int és uint-re működnek. A továbbiakban igazából olyan izgalmas dolgok nincsenek már. A frustum-okat nagyon könnyen meg lehet határozni, hiszen a síkegyenletről tudjuk, hogy kovariáns vektor, azaz: Tehát ha egy síkegyenletet screen spaceből vissza akarok transzformálni world space-be, akkor mindössze jobbról kell szorozni a viewproj mátrixxal. Most egyesek pánikba esnek, hogy na de a perspective division biztos bekavar... Nem kavar be, ha most kifejtjük a síkegyenletet clip space-ben, akkor: Tehát ha a viewproj-al való transzformáció után normalizálod a síkegyenletet, akkor tökéletesen működni fog. Ja és screen spaceben mik a síkegyenletek? Annyit segítek, hogy a teljes projekciós mátrixra a screen space-beli frustum egy [-1, 1]3 kocka. Azt felosztod a tile-oknak megfelelően (tipp: csak a d komponensben különböznek) és kiszámolod a síkokat. A végén még a láncolt listába való írkálásról kéne mondani valamit. A listát hátulról építem fel az alábbi módon: CODE
layout(binding = 0)
uniform atomic_uint nextInsertionPoint;
shared uint TileLightStart;
shared uint TileLightCount;
{
// ... folyt ...
for( work_item_fényeire )
{
if( bent_van_a_frustumban )
{
uint next = atomicCounterIncrement(nextInsertionPoint);
uint prev = atomicExchange(TileLightStart, next);
nodebuffer.data[next].LightIndexAndNext = uvec4(i, prev, 0, 0);
atomicAdd(TileLightCount, 1);
}
}
barrier();
if( gl_LocalInvocationIndex == 0 )
headbuffer.data[index].StartAndCount = uvec4(TileLightStart, TileLightCount, 0, 0);
}
A TileLightStart tehát arra szolgál, hogy tudjam melyik volt az előző listaelem helye (csak a helye kell), hiszen a következőnek beszúrt elem erre kell mutasson. A TileLightCount-ra valójában nincs szükség, de ha már úgyis ki van paddelve a struktúra, akkor legyen ott (debug célra). Az akkumuláló fragment shadert gondolom már nem kell bemutatni. Kiolvassa az SSBO-kból amit kell, és elvégzi a megvilágítást. Az aktuális tile meghatározható a gl_FragCoord-ból. A teljesítményről annyit, hogy a felbontástól és az egy tile-ra ható fények számától függ. Az utóbbihoz nyilván kapcsolódik a fények száma, sugara és a tile-ok mérete, de alapvetően nem a compute shader a lassú, hanem a fények rajzolása. Ehhez speciel nem kell compute shader, SSBO viszont ajánlott. Az előzőhöz képest ez sokkal egyszerűbb algoritmus, mert csak beleírja a láncolt listába a fragmenteket (mélységgel együtt), viszont egy bruteforce megoldásnak tekintendő. A klasszikus AMD implementációhoz képest tettem néhány eltérést, ugyanis:
 A láncolt listás bufferek teljesen hasonlóak mint fent, tehát van egy headbuffer (4 bájt per pixel elég) és egy nodebuffer (16 bájt per pixel elég). Na igen, de ha mondjuk 4 rétegig akarsz rendezni
és a képernyőd 1920×1080-as (1080p, fullHD), akkor egy gyors fejszámolással az 126 MB (+8 MB a fejelemeknek). Ha a packed layout működne, akkor 95 MB (+4 MB)-ra letolható,
de csak nVidia kártyákon működik rendesen (höfö dörömbölni az AMD-nél, hogy tanuljanak meg drivert írni).
Az std430-at nem próbáltam, az egy picit javíthat (fejelemek).
A láncolt listás bufferek teljesen hasonlóak mint fent, tehát van egy headbuffer (4 bájt per pixel elég) és egy nodebuffer (16 bájt per pixel elég). Na igen, de ha mondjuk 4 rétegig akarsz rendezni
és a képernyőd 1920×1080-as (1080p, fullHD), akkor egy gyors fejszámolással az 126 MB (+8 MB a fejelemeknek). Ha a packed layout működne, akkor 95 MB (+4 MB)-ra letolható,
de csak nVidia kártyákon működik rendesen (höfö dörömbölni az AMD-nél, hogy tanuljanak meg drivert írni).
Az std430-at nem próbáltam, az egy picit javíthat (fejelemek).
Egy további probléma, hogy sok "fölösleges" fragment is kikerül, hiszen az objektum rajzolásakor alapesetben nem látható részek is beleíródnak a bufferbe (melyeket az önmagával való z-test kiszórt volna egyébként). Az implementációmban jelenleg jelen van egy elég ronda z-fight szerű dolog, amit még nem tudtam kiküszöbölni, de lehet hogy ez okozza. Persze meg lehetne oldani egy kézi z test-el, de akkor meg az objektum saját részei nem látszanak át rajta, és a módszer nagyrészt értelmét veszti... (legalábbis a költségének fényében). Az eredeti algoritmushoz képest a következő dolgokban térek el:
CODE
uvec4 nodes[MAX_LAYERS + 1];
nodes[0].x = packUnorm4x8(color);
nodes[0].y = depth;
nodes[0].z = 0xFFFFFFFF;
nodes[0].w = 0;
// save list to nodes array (1..count)
// sort in private memory
for( uint i = 1; i < count + 1; ++i )
{
uint j = i;
while( j > 0 && nodes[j - 1].y < nodes[j].y )
{
tmp = nodes[j - 1];
nodes[j - 1] = nodes[j];
nodes[j] = tmp;
--j;
}
}
// copy back to list
Most furcsának tűnik, hogy miért másolom ki a lista elemeit, de így sokkal tisztább és érthetőbb a kód. A helyes működéshez a fejelemlistát inicializálni kell glClearBufferData-val vagy shaderrel (speciel az előbbi jobban hangzik). Helytakarékosságból a fragment színét be lehet tömöríteni uint-be a packUnorm4x8 függvénnyel. Ami egy sokkal lényegesebb dolog, az maga az alpha blending. Nézzük először mi történne normál esetben: final_color = mix( ... mix(mix(bg, c1, a1), c2, a2) ..., cn, an); final_color = ( ... (bg * (1 - a1) + c1 * a1) * (1 - a2) + c2 * a2) * ... * (1 - an) + cn * an Ha most ezt kifejtem, akkor: final_color = bg(1 - a1)(1 - a2)...(1 - an) + c1a1(1 - a2)...(1 - an) + ... + cnan Legyen: accum_alpha = (1 - a1)(1 - a2)...(1 - an) accum_color = c1a1(1 - a2)...(1 - an) + ... + cnan Ezt adja ki az akkumuláló fragment shader és ekkor final_color = bg * accum_alpha + accum_color, ami megfelel annak, hogy glBlendFunc(GL_ONE, GL_SRC_ALPHA)-t hívsz. A fragment shader kódja innen már kitalálható. A memóriahasználathoz annyit tudok hozzáfűzni, hogy lehet több lépésben is csinálni ezt a dolgot (pl. felosztani a képernyőt 4 csempére), de annak tejesítménybeli ára van, hiszen annyiszor kell leküldeni a geometriát. Egy rosszabb hír, hogy játékokban sok esetben közel sem elég 4 réteg. Szóval az okosabb módszerek még mindig menőbbek, lényeges látványbeli különbség nélkül. Ez megint egy olyan dolog amihez nem feltétlenül kell compute shader, hiszen van tessellation shader is, ami limitáltabban, de tudja ezt. Anyagot viszont nem találtam hozzá, úgyhogy compute shaderrel csináltam meg. A rend kedvéért idefirkálom a NURBS görbe definícióját: 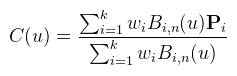
Ahol a Pi-k a kontrollpontok (k darab), n a görbe foka (k > n), a Bi,n-el jelölt bázisfüggvények pedig rekurzívan vannak megadva: 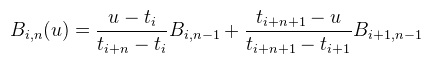
És a nulladfokú bázisfüggvény, ami a legtöbb problémát okozza: 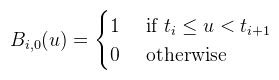
Ahol t1 ≤ ... ≤ tk + n + 1 az úgynevezett knot vektor, például { 0, 0, 0.1, 0.4, 0.4, 1 }. A nulladfokú bázisfüggvény tehát két megfelelő knot között (knot span) 1 máshol 0, egy n-edfokú pedig a hozzá tartozó n + 1 spanon nemnulla. Egy kicsit a görbe természetéről: egy adott pontra legfeljebb n + 1 kontrollpont hathat (ez később hasznos lesz). Hogy melyek, azt a knot vektor mondja meg. Tehát ahogy a paraméter (u) halad végig a knot spanokon, újabb kontrollpontok aktiválódnak, a régiek meg deaktiválódnak. Ha egy knot többször megjelenik (multiplicitás), az a görbe folytonos diffhatóságát csökkenti. Ha egy knot multiplicitása n + 1, akkor a hozzá tartozó egyetlen kontrollpontban a görbe nem diffható többé (C0 folytonos). Na de miért rossz ez a definíció? Például azért, mert egyik irodalom se írja le, hogy u honnan a fenéből van. Jajj dehát biztos a [0, 1] intervallumból... hát nem. Meg azért is, mert a bázisfüggvényekben simán oszthat 0-val, és azt 0-nak kell tekinteni, különben nem működik. Ha most ránézünk a görbe képletére akkor ott van a nevezőben egy normalizációs faktor (NF), amiről pongyola módon azt gondolná az ember, hogy sosem lehet nulla (hacsak minden súly nulla), sőt a legtöbb irodalom figyelembe se veszi, hogy nulla lehet. A nagyobbik probléma, hogy nemnulla értékek esetén is el tudja rontani a görbét (a folyt. diffhatóságát "véletlenül" lecsökkenti). A bázisfüggvényeknek van egy olyan tulajdonsága, hogy adott u-ra az összegük 1 (partition of unity, egységosztás), és ezt a baromságot minden irodalom el is fogadja, mert egyik se csinálta meg soha. Nem, baromira nem mindig 1 az összegük, és ezzel meg is csinálom az első javítást a definíción: Persze, akkor mondani kell egy olyan esetet, amikor nem teljesül: bármely olyan knot vektor, amelyikben az első vagy utolsó knot multiplicitása (m) nem n + 1. Általánosan a következő mondható (multiplicitástól függetlenül): 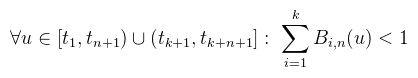
(sőt, ekkor nem csak az n-edfokú szumma ilyen, hanem minden j ≥ m -edfokú is) Tehát ilyen u-kra nem teljesül az egységosztás tulajdonság, de rögtön látszik is a megoldás, azaz hogy u csak a tn+1 és tk+1 knotok között veheti fel az értékét. Az ilyen "rossz" görbék nem érnek el egészen az első és utolsó kontrollpontig, hanem előbb abbamaradnak. Van azonban még egy javításra szoruló dolog, mégpedig az utolsó felvehető érték (tk+1) esete. Ezt ugyanis a nulladfokú bázisfüggvény nem kezeli le, márpedig jó lenne, ha a "jó" görbék az utolsó kontrollpontot érintenék. Ezt elég pongyolán lehet garantálni: Tehát tk+1 beleértendő abba a spanba. Ez felületeknél különösen fontos, mert ha nem veszed bele, akkor a normálvektorban egy ronda törés lesz a felület vége felé. Most, hogy két hét alatt sikerült megjavítanom ezt a fanbasztikus definíciót, jöjjön a lényeg: hogyan lehet compute shaderrel feltesszellálni egy görbét/felületet (csak egyenletes tesszellációval foglalkozok). A számolásban a legtöbb időt a bázisfüggvények redundáns kiértékelése viszi, viszont ezzel a trükkel ki lehet vinni a ciklusból. Ehhez a bázisfüggvényeket át kell írni a hatványbázisba, és akkor a paperben szereplő képlettel előre kiszámolhatóak a Ci,n,j együtthatók. A hatványbázisban felírt bázisfüggvény így: 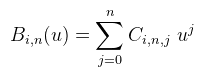
Ezek az együtthatók függetleníthetők u-tól, ugyanis az egész buli a nulladfokú bázisfüggvényre épül, ami viszont adott u-ra csak egy spanon nemnulla. Mivel egy adott spanban csak n+1 kontrollpont van hatással a görbére, elég spanonként ennyi darab tömbben  eltárolni az együtthatókat, sőt ezt
a workgroup lokális memóriájába lehet pakolni (amíg befér).
Még egy jó hír, hogy hatványbázisban baromi könnyű (parciális) deriváltat számolni, ami a normálvektorhoz kell.
eltárolni az együtthatókat, sőt ezt
a workgroup lokális memóriájába lehet pakolni (amíg befér).
Még egy jó hír, hogy hatványbázisban baromi könnyű (parciális) deriváltat számolni, ami a normálvektorhoz kell.
Van azonban egy rossz hír is: a GLSL nem tud rekurziót (HLSL sem, OpenCL és CUDA viszont igen, amit nem egészen értek, de mindegy...). Szóval ezt a vidám trükköt először át kell írni iteratívra. Ez könnyen megtehető, hiszen csak Ci,0,0-ból kell kiindulni és minden köztes lépést eltárolni egy (n+1)3 méretű tömbben. Ez szintén elfér a shared memoryban (a szabvány minimum 32 KB-ot követel meg). Ezt pongyolán blossom-nak neveztem el, de nem biztos, hogy ez a pontos felírása a polárformának. Egy másik GLSL hiányosság az, hogy a makró kifejezéseket nem értékeli ki előre. Szintén egy hibagyanús dolog a többdimenziós tömb, éppen ezért mindent kézzel érdemes kiszámolni. Eddig az AMD-t szidtam, most viszont az nVidia-t fogom ugyanis a user-defined függvényeket rosszul fordítja, ha shared változó a paramétere... Szóval igaz a mondás, miszerint a shader fordító abszolút megbízhatatlan. Az együtthatók meghatározása után már elég egyszerű a dolog: a work groupon belül elosztva ki kell számolni a görbe pontjait:
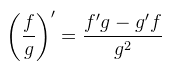
Nos igen...sok sikert kiszámolni. Nem tudom milyen megfontolásból, de egyik implementáció sem számolja ki rendesen (le kell scrollozni a tesszellációs samplehoz), hanem valami olyat csinál, ami csak nekem láthatóan rossz (rosszul deriválják le). Úgyhogy akkor én most megcsinálnám jól. Namost, mivel a képlet baromi hosszú és nem fér ki, valahogyan rövidítenem kell. Legyen az eredeti képlet: 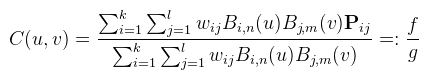
Ezzel a jelöléssel akkor az u szerinti parciális derivált: 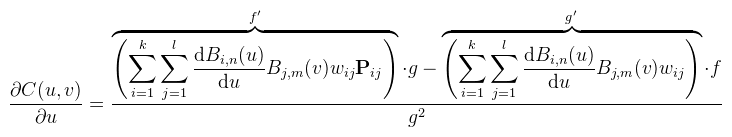
v-re nyilván hasonló. Ezt a négy részt (f, f', g, g') külön ki lehet számolni (ez elsőre nekem sem volt nyilvánvaló), így az egész buli egy (dupla)szummában elvégezhető. Mint említettem, a bázisfüggvényeket könnyű lederiválni; sőt harmadfokúig még valamennyire GPU barát is, mert: CODE
shared vec4 CoeffsU[MAX_ORDER * MAX_SPANS]; // Ci,n,j együtthatók (max 4 * 13 most)
shared vec4 CoeffsV[MAX_ORDER * MAX_SPANS];
// kiszámolja a tangenseket egy adott (u, v)-re
void CalculateTangents(out vec3 tangent, out vec3 bitangent, float u, float v)
{
vec4 Upoly = vec4(1.0, u, u * u, u * u * u);
vec4 dUpoly = vec4(0.0, 1.0, 2.0 * u, 3.0 * u * u);
vec4 Vpoly = vec4(1.0, v, v * v, v * v * v);
vec4 dVpoly = vec4(0.0, 1.0, 2.0 * v, 3.0 * v * v);
uint spanU = FindSpan(u);
uint spanV = FindSpan(v);
vec3 f = vec3(0.0);
vec3 dUf = vec3(0.0);
vec3 dVf = vec3(0.0);
float dUg = 0.0;
float dVg = 0.0;
for( int i = 0; i < orderU; ++i ) // k szumma (n + 1 elég)
{
for( int j = 0; j < orderV; ++j ) // l szumma (m + 1 elég)
{
index1 = spanU * MAX_ORDER + i;
index2 = spanV * MAX_ORDER + j;
float c = dot(CoeffsU[index1], Upoly) * dot(CoeffsV[index2], Vpoly) * weight;
float cdU = dot(CoeffsU[index1], dUpoly) * dot(CoeffsV[index2], Vpoly) * weight;
float cdV = dot(CoeffsU[index1], Upoly) * dot(CoeffsV[index2], dVpoly) * weight;
f += controlPoints[...] * c;
g += c;
dUf += controlPoints[...] * cdU;
dVf += controlPoints[...] * cdV;
dUg += cdU;
dVg += cdV;
}
}
tangent = (dUf * g - dUg * f) / (g * g);
bitangent = (dVf * g - dVg * f) / (g * g);
}
Az így kapott két tangensvektorból a normál már előáll egy vektoriális szorzattal. Harmadfokúnál nagyobbra dot helyett már ciklust kell használni (vagy meggondolni, hogy hogyan lehet mégis dotolni). Mivel egy NURBS felület két NURBS görbe tenzorszorzata, ezért pongyola módon ugyanazt a görbét tenzorszoroztam önmagával. A felület kontrollpontjait a két görbe kontrollpontjaiból számoltam ki, de általános módszer erre nincs (sajnos). Általában ezeket kézzel szokás megadni. Néhány megjegyzés: az indexbuffert std430-nak érdemes deklarálni (de ez csak 4.3-tól van), mert az nem paddeli ki 16 bájtra az egyébként érvényes struktúraméretet (uvec2 például érvényes, uint[6] szintén). Egy másik fontos dolog, hogy a glLineWidth megszűnt (van, de nem működik), úgyhogy vonalakat már csak geometry shaderrel lehet rendesen rajzolni. Ezekkel minimálisan foglalkoztam, de nem implementáltam le, mert soká tart vagy körülményes jól belőni. Igazából elég kevés olyan dolog van grafika témakörben amire értelmesen lehet használni a GPGPU-t, mert a legtöbb algoritmust
a fragment shader is meg tudja csinálni.
1) az eredeti algoritmus egy fullscreen pass-ban form factor-okhoz hasonló számolást végez. Nagyon sok mintavételezés kell (200-400 pixelenként), így elég lassúcska és annyira nem is néz ki jól. Árnyékokat nem tud.
2) a forward+ (vagy tile-based deferred) renderert felhasználva kipakolni sok kis pont fényt. Szerintem ez egy tévedés, bár az AMD mintha pont ezt csinálná... aztán compute shaderrel még hozzá lehet pakolni indirekt árnyékokat.
Bár egy bounce-os GI-t meg tud csinálni, nekem nem tetszik...tetszőleges jelenetet nem lehet vele bevilágítani, mert a RSM-re van limitálva (tehát egy kívülről besütő napfény sosem fog tovább pattogni a kisszobába). Lightmap/vertex light gyorsabb számolása: a GPU-ról CPU-ra való transfert ki lehet spórolni, ehhez viszont a lightmapnek is és a sample-ket tartalmazó buffernek is olyannak kell lennie ami átfordítható compute shaderes logikára. Lényegesen nem gyorsít rajta, mert a bottleneck nem ez, hanem hogy rengeteg sample-t kell csinálni. Raytracing: szerintem nem erre való a GPU... Módszerek már vannak (a paper szerint BVH térfelosztással), de a problémákat ezzel nem oldod meg (global illumination-t legalább olyan nehéz belevinni, mint raszterizálással). Path tracing: erre is van már realtime implementáció, de én szkeptikus vagyok. Maga a módszer Monte Carlo alapú, tehát konvergálnia kell (akkor szép a kép ha nem mozogsz, egyébként mákos). Cloth simulation: videó nincs is róla, paper viszont van. Érteni kell fizikához. Ezeknek a (jövőbeli) használatát érdemes meggondolni. Nyilván sokkal több van, de itt csak azokat említem meg, amik szerintem is hasznosak.
A cikkből is látható, hogy értelmesen csak nVidia kártyán sikerült használnom az új extensiönöket. Az említett Radeon 6750M-en nem hajlandó működni az SSBO, csak akkor ha használat után kiolvasom a tartalmát
(lehet, hogy ez az első kvantum GPU?).
Ez persze nem jelenti azt, hogy az AMD-nek szar kártyái vannak (dehogynem), csak annyit, hogy szar OpenGL drivereket ír.
A DirectX drivereik szerencsére stabilabbak, sőt ott van nekik a Mantle is (amit viszont a kutya nem használ).
Irodalomjegyzék http://www.crytek.com/download/2014_03_25_CRYENGINE_GDC_... - The Rendering Technology of Ryse (Crytek, 2014) https://www.khronos.org/assets/uploads/developers/library/... - OpenGL 4.3 Birds Of a Feather (SIGGRAPH 2012) http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2012/10/... - DirectCompute by Example (AMD, 2012) http://bps11.idav.ucdavis.edu/talks/11-towardInteractiveGlobalIllumination... - Interactive Global Illumination (SIGGRAPH, 2011) http://www.nvidia.com/content/siggraph/Rollin_Oster_OpenGL_CUDA.pdf - OpenGL & CUDA Tessellation (nVidia, 2011) http://www.dice.se/wp-content/uploads/2014/12/... - DirectX 11 Rendering in Battlefield 3 (DICE, 2011) http://developer.amd.com/wordpress/media/2012/10/... - Technology Behind AMD's "Leo demo" (AMD, 2010) http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html - CUDA programming guide (nVidia) http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf - Kepler architecture (nVidia) |
