|
A 2016-os év ismét forradalmat hozott a 3D grafika programozásban, ugyanis megjelentek az új generációs, nagyon hardverközeli API-k (DirectX 12, [Metal], Vulkan). Azt gondolná az egyszerű programozó, hogy az indokolatlan hype miatt a sokáig szeretett OpenGL megkezdi jól megérdemelt nyugdíjas éveit, és az unokáinknak fogunk majd csak anekdotákat mesélni, mint például: "aAaaaAaaa réÉégi szép időŐőkben, amikor lefagyasztottam a számítógéÉéépet egy rossz ópengéÉéel hívássaaAal..."
Tartalomjegyzék
Röviden összefoglalnám, hogy a 3.2 előtti verziókhoz képest mi változott. Core profile kontextet ugyanis csak 3.2-től lehet létrehozni, de valódi core profile-nak a 3.3-as verziót tekintem. Az alábbi szabályok innentől kezdve kötelezőek (ezekről majd részletesebben is írok):
A Windows ebből a szempontból a butábbik oprendszer, ugyanis először létre kell hozni egy szokványos kontextet egy dummy ablakra; nehogy a tényleges ablakra hozd létre, mert a pixel format nem állítható be egynél többször! Ezután le kell kérdezni a megfelelő függvénypointereket, majd azokkal lehet létrehozni az új kontextet az alábbi módon: CODE
HDC hdc = ...; // az ablakhoz (HWND) tartozó device context
// WGL_ARB_pixel_format, WGL_ARB_create_context, WGL_ARB_create_context_profile szükségesek
wglGetPixelFormatAttribivARB = wglGetProcAddress("wglGetPixelFormatAttribivARB");
wglGetPixelFormatAttribfvARB = wglGetProcAddress("wglGetPixelFormatAttribfvARB");
wglChoosePixelFormatARB = wglGetProcAddress("wglChoosePixelFormatARB");
wglCreateContextAttribsARB = wglGetProcAddress("wglCreateContextAttribsARB");
// surface format kiválasztása
int attribs[] = {
WGL_DRAW_TO_WINDOW_ARB, TRUE,
WGL_ACCELERATION_ARB, WGL_FULL_ACCELERATION_ARB,
WGL_SUPPORT_OPENGL_ARB, TRUE,
WGL_DOUBLE_BUFFER_ARB, TRUE,
WGL_PIXEL_TYPE_ARB, WGL_TYPE_RGBA_ARB,
WGL_COLOR_BITS_ARB, 32,
WGL_ALPHA_BITS_ARB, 0,
WGL_DEPTH_BITS_ARB, 24,
WGL_STENCIL_BITS_ARB, 8,
0
};
int pixelformat = -1;
UINT numformats = 0;
wglChoosePixelFormatARB(hdc, attribs, 0, 1, &pixelformat, &numformats);
PIXELFORMATDESCRIPTOR pfd = { ... }; // hasonlóan kitöltve, mint attribs
SetPixelFormat(hdc, pixelformat, &pfd);
// kontext létrehozás
int contextattribs[] = {
WGL_CONTEXT_MAJOR_VERSION_ARB, 3,
WGL_CONTEXT_MINOR_VERSION_ARB, 3,
WGL_CONTEXT_FLAGS_ARB, 0, // vagy WGL_CONTEXT_DEBUG_BIT (csak 4.3-tól)
WGL_CONTEXT_PROFILE_MASK_ARB, WGL_CONTEXT_CORE_PROFILE_BIT_ARB,
0
};
HGLRC hrc = wglCreateContextAttribsARB(hdc, NULL, contextattribs);
wglMakeCurrent(hdc, hrc); // aktiválás
(megj.: a vízilovas viccet meséltem már?) A WGL_CONTEXT_FORWARD_COMPATIBLE_BIT_ARB flaget nem kell megadni, ugyanis 3.3 óta minden régi funkcionalitás implicit módon ki van hajítva. Ez egy rövidített kód, mert nem szeretnék túl sok helyet elhasználni, éppen ezért külön felüdülés, hogy macOS-en (korábban OS X) sokkal rövidebb a kód. Hátrány viszont, hogy csak kétféle verziót enged: 3.2 vagy 4.1... Nagyon remélem, hogy a 3.2-es is tudja a 3.3-as funkcionalitást, mert ha nem, akkor rövid időn belül bajban leszek... (megjegyzem, ha a kártya tud 4.1-et, akkor a válasz igen): CODE
NSView* view = ...; // ez tulajdonképpen a HWND/HDC megfelelője
NSOpenGLPixelFormatAttribute attributes[] = {
NSOpenGLPFAColorSize, 24,
NSOpenGLPFAAlphaSize, 8,
NSOpenGLPFADepthSize, 24,
NSOpenGLPFAStencilSize, 8,
NSOpenGLPFADoubleBuffer,
NSOpenGLPFAAccelerated,
NSOpenGLPFANoRecovery,
NSOpenGLPFAOpenGLProfile, NSOpenGLProfileVersion3_2Core,
0
};
NSOpenGLPixelFormat* format = [[NSOpenGLPixelFormat alloc] initWithAttributes:attributes];
NSOpenGLContext* context = [[NSOpenGLContext alloc] initWithFormat:format shareContext:nil];
[context setView:view];
// ez nem kötelező, de retina display esetén szükséges
if ([view respondsToSelector:@selector(setWantsBestResolutionOpenGLSurface:)]) {
[view setWantsBestResolutionOpenGLSurface:YES];
}
[context update]; // ha valami változik a kontexten, akkor ezt meg kell hívnod
[context makeCurrentContext]; // aktiválás
Ennyi szerintem bőven elég a kontext létrehozásról, a részletekért ld. a kódmellékletet. Az extension-ök lekérdezésében azonban változás állt be (mert miért is ne), így mostantól két opciód van:
CODE
GLint numext = 0;
const char* name = "GL_ARB_..."; // amit le szeretnél kérdezni
glGetIntegerv(GL_NUM_EXTENSIONS, &numext);
for( GLint i = 0; i < numext; ++i ) {
ext = (const char*)glGetStringi(GL_EXTENSIONS, i);
if( 0 == strcmp(ext, name) )
return true; // támogatott
}
Amint látható, egy új függvény került a képbe glGetStringi néven, amit természetesen ugyanúgy le kell kérdezned; szerencsére csak Windows-on. Megemlítendő, hogy az EXT és hasonló szuffixeket nem kell (nem szabad) megadni, hacsaknem a kívánt extension nem része az adott verziónak (pl. GL 4.6 előtt az anizotróp szűrés ilyen). Még lényegesebb, hogy macOS-en a core profile-ba már bevett kiterjesztéseket le se lehet kérdezni (tehát explicit módon létezőnek tekintendőek)! Ha ezeken a lépéseken túljutottál (és javaslom, hogy először ez működjön), akkor készen állsz fejest ugrani az API programozásába. Persze ez ahhoz hasonlít, mint amikor vízbe ugrasz fejest: rövid távolságon semmi bajod nem lesz, ha viszont elég magasról ugrasz le (kb. 150m), akkor a víz felületi feszültsége miatt ugyanaz fog történni, mintha betonnak ütköznél... Azért említem ezt meg, mert az egyik debug eszköz (RenderDoc) csak úgy tud több kontext esetén működni, ha azok meg vannak osztva. Ez olyasmi fogalom, mint az univerzumok a multiverzumban (gondolom hallottatok már erről). A shared context-ek egy multiverzumot alkotnak, aminek az egyik következménye például, hogy az erőforrásnevek (számok) generálása a multiverzumra nézve szekvenciális.
Mivel a shaderek használata kötelező lett, logikusnak gondoltam, hogy először azokat mutatom be, ebben a bekezdésben csak GL 3.3-hoz; az újdonságokat majd a további bekezdésekben említem meg. Szintaxist úgy a legkönnyebb bemutatni, ha rögtön kódot mutatok, úgyhogy vadul írjunk is egy vertex-fragment shader párost:
Amint látható (?), minden shader a #version makróval kell kezdődjön, mögéírva a használni kívánt GLSL verziót. GL 3.2-ben ez 150, onnantól fölfelé viszont az OpenGL verziója (azaz GL 3.3-ban 330). A kulcsszavak közül kikerült az attribute és a varying, helyettük az in és az out kulcsszavakat kell használni. A vertex input layout-ot mostantól csak így lehet megadni (azaz nincs többé gl_MultiTexCoord és hasonlók). Beépített vertex shader inputok a gl_VertexID illetve a gl_InstanceID. Ezek segítségével nem muszáj bufferben megadni az adatot, hanem generálható közvetlenül a shaderben. A vertex shader outputjai a gl_PerVertex nevű ún. interface block-ban vannak megadva, aminek egyik tagja a gl_Position, így az természetesen megmaradt. További outputok a már említett gl_ClipDistance[], melyet újra kell deklarálni a konkrét méretével, illetve a gl_PointSize ha valaki még használja... Fragment shader oldalról továbbra is input a gl_FragCoord; erről azt kell tudni, hogy a viewport terében van megadva (így különösen jól használható együtt a texelFetch() függvénnyel). Outputként csak a gl_FragDepth maradt meg, a kiadott színértékeket közvetlenül kell deklarálni és a glBindFragDataLocation() hívással hozzákötni a megfelelő framebuffer attachment-hez. A textúrából való olvasás egységesen a texture() függvénnyel történik, azaz nincs többé a nevében a sampler típusa. Ugyanez igaz a többi hasonló függvényre is (pl. textureGrad). A texelFetch() függvényhez szintén kell mintavételező, viszont a textúra koordináta egész szám (ez egyébként az ún. buffer texture-höz lett bevezetve; erről nem írok). Ezeken kívül megjelent a layout minősítő, például: CODE
layout(location = 0) in vec3 my_Position;
Ekkor nem szükséges lekérdezni OpenGL oldalon az attribútum helyét a glGetAttribLocation() hívással. Annyit elmondanék, hogy ez uniform-okra is használható, ekkor viszont a (shader) programra nézve kell ezeket szekvenciálisan megadni (mint vulkánban). Ha nem így adod meg és működik, az bug (nálam pl. sokáig működött, aztán egy lényegtelen változtatás után hirtelen mégsem). (megj.: ez abból adódik, hogy két fogalom is van az uniformok elérésére. Az egyik az index [ami feltehetően mindig a deklarációs sorrend szerint van], a másik a location. Ha felveszel egy új uniformot, akkor a korábbiak location-je megváltozhat. A hiba szerintem akkor nem jön elő, ha az index megegyezik a location-nel; de erre ne építs !!!) Egyéb layout minősítőkkel később foglalkozok. Az elinduláshoz ennél részletesebb ismertetésre nincs szükség. Megtévesztő név a VAO, ugyanis a régi OpenGL-ben létező fogalom a vertex array, ami az egyes vertex attribútumok tömbösített megadását tette lehetővé (glVertexPointer, glNormalPointer, stb.). A vertex array object-nek ehhez csak névlegesen van köze: ez is a vertex attribútumok tulajdonságait írja le (glVertexAttribPointer), viszont egy előre definiált objektumban. Az előnye az, hogy rajzoláskor elég csak ezt a bizonyos objektumot beállítani, szemben a régi módszerrel, ami az attribútumokat egyesével állítja be minden rajzolás előtt.
CODE
GLuint inputlayout = 0;
GLSizei stride = 24;
CODE
glGenVertexArrays(1, &inputlayout);
glBindVertexArray(inputlayout);
{
// létrehozás utáni első bind-oláskor történik a definíció
glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer);
glEnableVertexAttribArray(0);
glEnableVertexAttribArray(1);
glEnableVertexAttribArray(2);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, stride, (const GLvoid*)0); // in vec3 my_Position;
glVertexAttribPointer(1, 4, GL_UNSIGNED_BYTE, GL_TRUE, stride, (const GLvoid*)12); // in vec4 my_Color;
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, stride, (const GLvoid*)16); // in vec2 my_TexCoord0;
}
glBindVertexArray(0);
CODE
// rajzolás
glBindVertexArray(inputlayout);
glDrawArrays(...);
Innentől kezdve a VAO definiált és módosíthatatlan (nem igaz, GL 4.5-től módosítható). Kényelmesebb, mint a zárójelben levő részt állandóan elvégezni nem? Sőt, az bár igaz, hogy a konkrét vertex buffer része az állapotnak, de a mögötte levő adat nem! Azt tehát nyugodtan lehet módosítani később is. Na oké, de mi van, ha változó méretű adatom van (ami nem fér be egyben a bufferbe)? Amíg nem törlöd ki a vertex buffer-t, addig az OpenGL ad egy (nem szabványos) menekülési útvonalat a glBufferData() ismételt meghívásával; ekkor a régi tárolót megjegyzi (hiszen még használatban lehet) és allokál egy újat (buffer orphaning). Ez DirectX-ben is bevett szokás, amikor megadod a D3DLOCK_DISCARD flaget. De vajon hányszor lehet ezt eljátszani mielőtt szörnyethal a GPU? Mondhatjuk azt, hogy "a driverre van bízva", csak sajnos ez azt is jelentheti, hogy a driver egyszerűen nem csinálja meg (és mivel a szabvány szerint a régi tároló törlődik, nem is köteles megcsinálni). Másrészt eleve indokolatlan, hogy miért van a vertex buffer hozzákötve a VAO-hoz: semmilyen információt nem használ fel belőle. Lássuk hogyan néz ki egy modern (GL 4.4-es) megoldás: CODE
GLuint inputlayout = 0;
CODE
glGenVertexArrays(1, &inputlayout);
glBindVertexArray(inputlayout);
{
glBindVertexBuffers(0, 1, NULL, NULL, NULL);
glEnableVertexAttribArray(0);
glVertexAttribBinding(0, 0);
glVertexAttribFormat(0, 3, GL_FLOAT, GL_FALSE, 0); // in vec3 my_Position;
glEnableVertexAttribArray(1);
glVertexAttribBinding(1, 0);
glVertexAttribFormat(1, 4, GL_UNSIGNED_BYTE, GL_TRUE, 12); // in vec4 my_Color;
glEnableVertexAttribArray(2);
glVertexAttribBinding(2, 0);
glVertexAttribFormat(2, 2, GL_FLOAT, GL_FALSE, 16); // in vec2 my_TexCoord0;
}
glBindVertexArray(0);
CODE
// rajzolás
glBindVertexArray(inputlayout);
GLuint buffers[] = { vertexbuffer };
GLintptr offsets[] = { 0 };
GLsizei strides[] = { 24 };
// megj.: van glBindVertexBuffer() is
glBindVertexBuffers(0, 1, buffers, offsets, strides);
glDrawArrays(...);
Egyre inkább hasonlít a kód a Vulkan-hoz: innentől kezdve nem kell a driverre hagyatkozni, ha az adat mérete meghaladja a bufferét. Sőt, dinamikus adat esetén a driver munkáját (frame queueing) is tudom segíteni ha 2-3 vertex buffer-t előre létrehozok és round-robin módon mindig csak az aktuálisat módosítom. Mivel a két dolog eléggé hasonlít, egy bekezdésbe vettem, azonban ne felejtsük el, hogy az utóbbi (SSBO) csak GL 4.3-tól van. Maga a GLSL szintaxis megengedi a régi fajta uniformok használatát is (glUniformXX-el beállítva), a modern API-khoz viszont ez nem illeszkedik, tehát érdemes minél előbb áttérni az uniform buffer (UBO) használatára.
Először nézzük meg a kódot, utána pedig elmesélem, hogy miért baromi nehéz ezt jól használni:
(megj.: ha több shader stage is használja ugyanazt a blokkot, akkor írd ki elé a layout(shared) minősítőt) Láthatóan már a tördeléssel is gondjaim vannak...ha ez lenne az egyetlen gond, akkor még meg is bocsátanám. Shader oldalon az uniformokat egy már említett interface block definiálja, és bár hasonlít a C-ből ismert struktúrára, mégsem az. Ugyanis, amint a jobb oldalon látható, a program oldali hivatkozáskor nem a definiált változó (vsuniforms) nevét kell megadni, hanem az interfészblokk nevét (VertexUniformData). Ebből rögtön következik, hogy egy adott shader stage-en belül ez nem egy újrafelhasználható konstrukció (lenyeljük...). Na de mi a nehézség ebben, hiszen első ránézésre elég egyszerű kód...? Tömören megfogalmazva az adat módosítása, kicsit bővebben a glBufferSubData() működése. Azt gondolná az ember, hogy ez majdnem ugyanaz, mint vulkánban a vkCmdUpdateBuffer(), de sajnos nem. Addig rendben van, hogy ez is lemásolja a kapott adatot, ezután viszont (hardvertől függően) elindít egy aszinkron DMA transfer-t, aminek az a következménye, hogy szinkronizáció nélkül nem hívhatom meg ismételten ugyanarra a területre. Oké, akkor próbálkozzunk máshogy: CODE
glBindBuffer(GL_UNIFORM_BUFFER, uniformbuffer);
void* data = glMapBufferRange(GL_UNIFORM_BUFFER, 0, ..., GL_MAP_WRITE_BIT|GL_MAP_INVALIDATE_RANGE_BIT);
{
memcpy(data, ...);
}
glUnmapBuffer(GL_UNIFORM_BUFFER);
glBindBufferBase(GL_UNIFORM_BUFFER, 0, uniformbuffer);
Erről legalább tudni lehet, hogy (most éppen) blokkol, emiatt persze kb. fele olyan gyors, mint az előző megoldás. A kulcs mindenesetre ez a hívás lesz (glMapBufferRange), mégpedig azért, mert rendkívül jól paraméterezhető. Tekintsük át a (GL 3.3-ban) megadható flageket:
Az UBO egyéb hátrányai a fentieken kívül, hogy fix és limitált a mérete (ált. 64 kB), illetve csak olvasható. A célnak ez általában elég, viszont kiterjesztve a fogalmat felmerül az igény arra, hogy sokkal nagyobb méretű adatot is fel lehessen dolgozni (akár írni!) a shaderben. GL 4.3-tól erre használható a shader storage buffer (SSBO). Ahogy az előbb, egy példán keresztül mutatom meg ezt is:
Láthatóan a GL 4.3 shader oldalról is sokkal fejlettebb, például rögtön megadható a binding (UBO-kra is természetesen). Az std140 egy ún. memory layout, ami azt mondja meg, hogy hogyan legyenek az adattagok igazítva; jelen esetben 16 B-os határokra. Ha szabványosan szeretnéd tömöríteni az adatot, akkor GL 4.3-tól elérhető az std430 is, ami lehetőség szerint 4 B-os határokra igazít, viszont csak SSBO-val használható. A packed-et inkább ne használd, mert hardverfüggő. Az std140 és az std430 egyben shared is, tehát utóbbit nem kell külön kiírni. Megjegyezném, hogy bár sokféle fajta buffer típus létezik, maga a buffer fogalom OpenGL-ben sem típusos! Tehát tetszőleges buffert beállíthatok a glBindBufferBase() hívással, mint SSBO (de akár atomic counter-ként is). Gyakorlati példákat lehet találni a későbbi, compute shaderek-ről szóló cikkemben, úgyhogy tovább nem részletezem a használatot. Helyette ismertetek egy új megoldást (GL 4.4) az említett lassúsági problémára, amit persistent mapping-nak hívnak. Ez arról szól, hogy az adatot a program elején leképezem CPU oldalra, majd közvetlen glFlushMappedBufferRange() hívásokkal jelzem a GPU-nak, ha módosítottam. De van egy még jobb hír: egy perzisztens leképezés lehet koherens is, amely esetben még csak jelezni sem kell a GPU-nak. Vigyázzunk azonban, mert bár az OpenGL szabvány ezt kimondja, nem jelenti azt, hogy a kártya tényleg tudja (Vulkan-ban ez könnyen ki is deríthető). Tehát ez a fajta megoldás is hardverfüggő, a hatékonysága viszont szinte garantált. Azért csak "szinte", mert ha egy koherens leképezést (ún. write-combined memory) olvasni és írni is akarsz, akkor bizony bitang lassú lesz. CODE
GLuint uniformstorage = 0;
void* persistentdata = 0;
CODE
glGenBuffers(1, &uniformstorage);
// allokálás és leképezés
glBindBuffer(GL_UNIFORM_BUFFER, uniformstorage);
glBufferStorage(
GL_UNIFORM_BUFFER, ..., NULL,
GL_DYNAMIC_STORAGE_BIT|GL_MAP_WRITE_BIT|GL_MAP_PERSISTENT_BIT|GL_MAP_COHERENT_BIT);
persistentdata = glMapBufferRange(
GL_UNIFORM_BUFFER, 0, ...,
GL_MAP_WRITE_BIT|GL_MAP_PERSISTENT_BIT|GL_MAP_COHERENT_BIT);
CODE
// feltöltés és rajzolás
*persistentdata = ...;
glBindBufferBase(GL_UNIFORM_BUFFER, 0, uniformstorage);
A felhasználható arzenál tehát elég nagy, viszont sok kártya nem támogatja ezen újdonságokat. Ez leginkább macOS-en igaz olyan kártyákkal, amik még nem tudnak Metal-t, a legmagasabb OpenGL verzió pedig (az Apple lustasága által) meg van rekedve 4.1-en. Ez gyakorlatilag minden 2012 előtti Mac gépre igaz. Üljünk akkor vissza a tervezőasztalhoz. A kimondott verzió GL 3.3, szeretnénk baromi gyorsan uniform adatokat frissíteni, sőt szélsőséges esetben stream-elni (egy frame alatt többször módosítani ugyanazt a buffert). Ha eleve a Vulkan filozófiájával gondolkozunk, akkor egyértelmű, hogy az uniform adatokat osztályozni kell az (egy frame-en belüli) sűrűségük szerint. Például a view/projection mátrixokat tipikusan egyszer állítod be, viszont a world mátrixot rajzolóhívásonként!
CODE
#define UNIFORM_COPIES 512 // ennyi rajzolóhívásonként szinkronizálok
struct EffectUniformBlock;
GLsync sync = 0;
GLuint ringbuffer = 0;
int currentcopy = 0;
CODE
glBindBuffer(GL_UNIFORM_BUFFER, ringbuffer);
glBufferData(GL_UNIFORM_BUFFER, UNIFORM_COPIES * sizeof(EffectUniformBlock), NULL, GL_DYNAMIC_DRAW);
CODE
// streamelt feltöltés (for 1:1000)
if( currentcopy >= UNIFORM_COPIES ) {
sync = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);
}
GLintptr baseoffset = currentcopy * sizeof(EffectUniformBlock);
if( sync != 0 ) {
GLenum result = 0;
GLbitfield waitflags = GL_SYNC_FLUSH_COMMANDS_BIT;
do {
result = glClientWaitSync(sync, waitflags, 500000);
waitflags = 0;
} while( result == GL_TIMEOUT_EXPIRED );
glDeleteSync(sync);
sync = 0;
currentcopy = 0;
baseoffset = 0;
}
glBindBuffer(GL_UNIFORM_BUFFER, ringbuffer);
GLbitfield flags = GL_MAP_WRITE_BIT|GL_MAP_INVALIDATE_RANGE_BIT|GL_MAP_UNSYNCHRONIZED_BIT;
void* data = glMapBufferRange(GL_UNIFORM_BUFFER, baseoffset, sizeof(EffectUniformBlock), flags);
{
memcpy(data, ...);
}
glUnmapBuffer(GL_UNIFORM_BUFFER);
glBindBufferRange(GL_UNIFORM_BUFFER, 0, ringbuffer, baseoffset, sizeof(EffectUniformBlock));
glDrawArrays(...);
++currentcopy;
Első látásra ez bizony kemény. A cikk elején említettem, hogy GL 3.3-ban is van lehetőség alacsony szintű hardverprogramozásra; hát most látjuk is, hogy mit jelent ez. Az OpenGL egyetlen szinkronizációs objektuma a GLsync, ami bár általános fogalom, csak egyetlen fajtája hozható létre, mégpedig a fence. Megjegyzem, ez majdnem ugyanaz, mint a vulkános fence (GPU és a CPU között szinkronizál). Azért csak majdnem, mert GL-ben használható semaphore-ként is (glWaitSync), ezt a glBufferSubData() esetén kell(het) használni. (megj.: létezik egyébként barrier is, de azt a glMemoryBarrier() függvény végzi el) Kezdjük ott, hogy mit jelent a ringbuffer: ciklikus buffer, azaz ha betelt, akkor egy szinkronizáció után újra elkezdem feltölteni. A kódrészlet tetszőleges számú rajzolóhívásra működik, az egyetlen megfontolandó dolog, hogy mennyi memóriát szeretnél feláldozni ennek a ringbuffer-nek. Ez természetesen az uniform adatok méretétől függ. A szinkronizáció azt jelenti, hogy a (lehetőleg) legutolsó utasítás után, ami a buffert használja meghívom a glFenceSync() függvényt, ami beilleszt egy várakozási pontot (fence) a command stream-be (de ő maga természetesen nem vár). A várakozást én kezdeményezem egy glClientWaitSync() hívással. Nem mindegy tehát, hogy mikor raktad be ezt a bizonyos várakozási pontot! Könnyen csökkenhet a hatékonysága, ha például rögtön a várakozás előtt rakod be. Egy további megemlítendő, bár intuitív dolog a glBindBufferRange() hívás. Ahogy a nevében is benne van, ez a buffernek csak a megadott régióját állítja be, tehát a drivernek úgymond "bizonyítom", hogy tényleg csak azt a részt akarom kirajzolni, amit módosítottam (így nem fog fölöslegesen szinkronizálni). Amikor ugyanazt az objektumot többször szeretnéd kirajzolni minimálisan eltérő tulajdonságokkal (pl. transzformációs mátrix), akkor azt instancing-nak hívják. Magyarra ezt valahogy úgy lehetne lefordítani, hogy "példányozás", de elég hülyén hangzik, úgyhogy maradok az angol nevénél. Sokféle technika van, ami ehhez kötődik; megpróbálom időrendben felsorolni őket:
CODE
GLuint vertexbuffer = ...; // vertex adat
GLuint instancebuffer = ...; // instance adat
GLuint inputlayout = 0;
GLuint vertexstride = 24;
GLuint instancestride = 64;
CODE
glGenVertexArrays(1, &inputlayout);
glBindVertexArray(inputlayout);
{
// vertex layout
glBindBuffer(GL_ARRAY_BUFFER, vertexbuffer);
glEnableVertexAttribArray(0);
glEnableVertexAttribArray(1);
glEnableVertexAttribArray(2);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, vertexstride, (const GLvoid*)0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, vertexstride, (const GLvoid*)12);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, vertexstride, (const GLvoid*)24);
// instance layout
glBindBuffer(GL_ARRAY_BUFFER, instancebuffer);
glEnableVertexAttribArray(3);
glEnableVertexAttribArray(4);
glEnableVertexAttribArray(5);
glEnableVertexAttribArray(6);
glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, instancestride, (const GLvoid*)0);
glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, instancestride, (const GLvoid*)16);
glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, instancestride, (const GLvoid*)32);
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, instancestride, (const GLvoid*)48);
glVertexAttribDivisor(3, 1);
glVertexAttribDivisor(4, 1);
glVertexAttribDivisor(5, 1);
glVertexAttribDivisor(6, 1);
}
glBindVertexArray(0);
CODE
// rajzolás
glBindVertexArray(inputlayout);
glDrawArraysInstanced(GL_TRIANGLES, 0, numvertices, numinstances);
(megj.: az instance adat VAO-ban való megadása megkerülhető UBO-val vagy SSBO-val) A glVertexAttribDivisor() a következőket mondja: ha a divisor nulla, akkor ugyanaz, mintha meg sem hívtam volna, azaz a rendes vertexekkel együtt kapom meg az instance adatokat is. Ha viszont nem nulla, akkor a kapcsolódó attribútumok akkor fogják a soron következő értéküket megkapni a shaderben, ha már divisor darab instance kirajzolódott. A mostani példában divisor = 1, azaz numinstances példányban fog megjelenni az objektum a képernyőn. Amikor a divisor más értéket vesz fel, akkor valamilyen más attribútum szerint is szeretném használni a technikát, de annak a frekvenciája kisebb. Például három példányonként új színt szeretnék megadni, ekkor a megfelelő attribútumnak a divisor-ja értelemszerűen 3. Amit észben kell tartani, hogy a hardware instancing hatékonysága függ az objektum poligonszámától, illetve a példányok számától. Kis poligonszámú objektumok (pl. fűszál) esetén eszméletlenül gyors tud lenni, ugyanis a vertex adat egyben befér a pre-transform cache-be. Nagy poligonszámú objektumok esetén a konyha instancing felé fog közelíteni teljesítményben, szélsőséges esetben lassabb is lehet (de ez többnyire csak régi kártyákon igaz). Általános szabály, hogy ha kevés példány van, akkor konyha instancing, ha közepesen sok példány van, akkor static instancing, ha nagyon sok példány van, akkor hardware instancing a nyerő (azonban elég sok példány esetén van egy fordulópont, ahol már lassabb). Amire viszont nem jó a hardware instancing, az ha példányonként textúrát akarok váltani. Azt ugyanis ebben a formában nem lehet megtenni. Ilyenkor a textúrákat pakold össze egy texture atlas-ba és a shaderben emuláld le a szükséges címzési módokat. Ezt nem fogom részletezni, mert rengeteg szabályt kell betartani, de természetesen megtehető. Alternatív megoldás a texture array, de akkor a textúrák mérete meg kell egyezzen. (megj.: ez a bizonyos megegyezés nem különösebben kritikus dolog: fölfelé nyugodtan skálázhatod a textúrákat, hiszen a tényleges jelenetben való felbontásuk a "normalizált" textúra koordinátáktól függ, viszont értelemszerűen memóriapazarló) A geometry shader nem megoldás a problémáidra az ARM/Mali szerint. Oké, ahol van SSBO, ott valóban emulálható vertex shader-rel (pl. Metal-ban), illetve adott esetben compute shader-rel. Én viszont nem értek egyet ezzel az állítással, egyrészt mert a Mali szoftveresen implementálja a geometry shader-t, ami csak annyit jelent, hogy olyan kütyükön ne használd. Másrészt a compute shader előtt/után mindenképpen szinkronizálni kell, míg a geometry shader a graphics pipeline része. Ezenkívül GL 4.3 alatt nincsenek az említett lehetőségek, szóval igenis sok esetben a geometry shader a jó választás.
(megj.: nem írtam el; gondoljunk bele, hogy a screen space az a [-1, 1]3 tartomány, tehát nem kell megfeleznem a vastagságot!) Na akkor szép sorjában: először is meg kell mondanom a shadernek, hogy milyen topológiájú adat jön be (most lines), illetve megy majd ki (point, line_strip, vagy triangle_strip). Azt is meg kell mondanom, hogy legfeljebb hány vertexet fogok generálni primitívenként (ugyanis a GPU így előre lefoglal magának egy buffert, amibe ezeket bele tudja pakolni). A shader inputjai hasonló interfészblokkban vannak megadva, mint a vertex shader outputjai, mivel azonban itt primitíveket kapok meg, a deklaráció egy gl_in[] nevű tömb. Ezen kívül természetesen megkapom a gl_PrimitiveID-t is (ha esetleg valamilyen buffert szeretnék címezni vele). A számolások után az alábbi függvényeket lehet meghívni:
Szintén érdemes tudni, hogy az, hogy én szomszédságot kapok meg, nem jelenti, hogy úgy is kell továbbadnom. Például egy 4 háromszögből álló szomszédságot átalakíthatok 4 darab tetraéderré (16 háromszög), vagy akár 3 darab vonalat egy négyszöggé (2 háromszög). Ez volt a bevezetés, most viszont jöjjön néhány GL 4.0 utáni újdonság. Először is, egy darab output stream helyett egyszerre többe is lehet írni (EmitStreamVertex); ez a transform feedback-ben hasznos (később). Ezen kívül a geometry shader is lehet instance-olt, ami azt jelenti, hogy egy adott bejövő primitívre többször futtatható. Ekkor az alábbi minősítőt kell megadni: CODE
layout(invocations = <amennyiszer szeretnéd>) in;
Limitáció van, de legalább 32 támogatott. Ekkor megkapod a hívás azonosítóját is (gl_InvocationID). Egyre inkább közeledünk a compute shader felé...most akkor miért is jó ez a geometry shader? Ha másért nem, akkor azért amit mondtam: a graphics pipeline-hoz tartozik, és emiatt olyan kitüntett tulajdonsága is van, hogy egyszerre több viewport-ba (gl_ViewportIndex) vagy egy rétegelt textúra (akár cubemap) több rétegébe (gl_Layer) is rajzolhat. Tehát bizonyos esetekben sokkal jobb választás, mint a compute shader (egy példa: cubemap alapú dinamikus tükröződés generálása). (megj.: metálban ezek a funkcionalitások ugyanígy megvannak, de a geometry shader-t/transform feedback-et emulálni kell) Egy ehhez kapcsolódó vicces fogalom a provokáló vertex (tudod, aki mindig beszól neked munka közben). Aki emlékszik még a flat shading-re, ott a raszterizált primitív összes fragmentje egy konkrét vertexből (a provokáló vertexből) kapja meg az adatait. A geometry shader szempontjából a viewport index vagy a layer lesz az, amit provokál (meg persze téged, hogy miért nem működik). Ha a driver megengedi, akkor ez program oldalon módosítható a glProvokingVertex() függvénnyel a primitív első vagy utolsó vertexére. Ha nem engedi meg, akkor nem tudhatod, szóval az a biztonságos megoldás, ha mindegyik kiadott vertexnek azt adod meg, amiben látni szeretnéd majd... Oké, de miért is akarnál mást...? Eddig nem mondtam el, de tetszőleges (fragment) shader adattagra kikapcsolható az interpoláció (pl. flat in vec3 wnorm;); ekkor az összes többi shader stage-ben is írd ki rá ezt a kulcsszót. Mivel egy adott topológián belül ez a változó tetszőleges értéket felvehet, nem mindegy, hogy melyik volt a provokáló vertex! A shadow volume-okkal foglalkozó cikkemben említettem, hogy a sziluettdetektálás és a shadow volume generálás átvihető geometry shader-be, ezáltal hardveresen gyorsítható. Ha viszont így szeretnéd megoldani, akkor különösen fontos, hogy az objektum ún. 2-manifold legyen. A GPU által lefoglalt buffer mérete ugyanis véges, azaz ha az objektum összes háromszögét egyesével húzod ki (meg nem nevezett program), akkor rövid idő alatt szörnyethal a videókártya (egy más jellegű dolog kapcsán ugyan, de tapasztaltam). Ez a témakör külön cikket érdemelne, de mivel megkértek rá, hogy foglalkozzak vele, röviden bemutatom a lényegét. A leggyakoribb felhasználási területe subdivision surface-ek, illetve parametrikus görbék és felületek előállítása. Általános célú háromszögelésre csak
Egy patch-et fogjunk fel úgy, mint vertexek sorozatát. Azt, hogy egy patch konkrétan hány vertexből áll, az előállítandó geometria határozza meg, de legalább 32 vertex garantálva van mint maximális hossz. OpenGL oldalon a glPatchParameteri() hívással kell megmondani, hogy hány vertexből álljon egy patch. A részletek előtt nézzünk meg egy shader kódot, ami harmadfokú Hermite görbéket tud rajzolni (azaz egy patch most 4 darab vertexből áll):
Oké, mi a búbánat ez? Először nézzük a TES-t, ugyanis ez mondja meg, hogy miket akarok generálni a patch-ből; most éppen vonalakat (isolines), egyenletes felosztással (equal_spacing). Ezen kívül megadható még winding order is (cw vagy ccw), nyilván akkor, amikor háromszögeket/négyszögeket generálsz. Itt egy pillanatra álljunk meg. Említettem a tessellation primitive generator-t, ami ezen két shader között fut le, azonban fontos tudni róla, hogy abszolút nem érdekli, hogy bejövő patch konkrétan micsoda, vagy hogy hány vertexből áll. A generálás egy ún. absztrakt patch-en dolgozik, aminek a típusát a TES-ben megadott topológia határozza meg:
Ha még nem vesztettétek el a fonalat, akkor most átugranék a TCS-re. Ennek kitüntetett tulajdonsága, hogy bejövő patch hosszát módosíthatja (azaz hozzáadhat vagy elvehet belőle vertexeket). Ezt figyelmbe véve erősen hasonlít egy compute shader-re: annyiszor fut le, amennyi a kimenő patch hossza (gl_InvocationID). A hasonlóság abban is megmutatkozik, hogy az egyes TCS futások olvashatják egymás kimenetét, illetve írhatják az adott patch-re vonatkozó kimenő változókat (pl. patch out vec4 valami); ehhez nyilván szinkronizálni kell a futások között, ami a barrier() utasítással tehető meg. (megj.: metálban egy compute shader tölti be a TCS szerepét, ezután megtörténik a generálás, és a vertex shader lesz a TES) A TCS-t nem kötelező megadni; ekkor OpenGL oldalon állíthatóak be a (patch szintű) kötelező ún. tesszellációs szintek (külső és belső). Az egyes TES topológiákra lebontva:
Vonalak esetén, mint mondtam az absztrakt patch tere egy vonalakból álló négyzet: a két külső tesszellációs szint ennek az éleire vonatkozik: gl_TessLevelOuter[0] azt mondja meg, hogy hány darab vonal generálódjon egy patch-ből (mindig equal_spacing), gl_TessLevelOuter[1] pedig ezeknek a részletességét mondja meg (hány szegmensből álljon). A maximális szegmensek száma legalább 64 (GL_MAX_GEN_TESS_LEVEL). Az egyes felosztástípusok a következőket jelentik az absztrakt patch-ben:
A példában egy görbét generáltam (gl_TessLevelOuter[0] = 1), de nyilván lehet többet is: ekkor a TES-ben gl_TessCoord.y mondja meg, hogy melyik vonalra fut éppen (de vigyázat, ez a [0, 1) intervallumban van megadva!). Emellett persze tetszőleges számú patch leküldhető, tehát nyugodtan lehet bármiféle spline-t csinálni, akár úgy is, hogy az egyes részgörbék több algörbéből állnak. A képen egy harmadfokú Hermite spline látható, 7 darab patch-ből. 
Egy további kérdés volt, amivel a korábbi cikkemben nem foglalkoztam, hogy használható-e ez NURBS generálásra. Mivel az is parametrikus görbe, szerintem igen (a súlyokat és a knot vektort uniformként lepasszolva). A GLSL nem tud rekurziót, tehát a görbe együtthatóit továbbra is át kell alakítani polárformába. Szintén figyelmbe kell venni, hogy a patch-ek nem tudják elérni egymás adatait, szóval vagy redundánsan kell megadni a kontrollpontokat, vagy szintén uniformként elérhetővé tenni, vagy az összes kontrollpontot egy patch-ben leküldeni (de akkor 32 a maximum). Elsőre bonyolultnak tűnő dolog, ugyanis az eddigi OpenGL oldali (shader) program használatot szinte teljesen áttúrja. Ne gondolja tehát senki, hogy a core profile egzakt és megingathatatlan szabvány...tulajdonképpen egy ideje ugyanaz a helyzet, mint ami előtte volt; lassan araszolva a Vulkan felé...
CODE
GLuint vertprogram = 0;
GLuint geomfragprogram = 0;
GLuint progpipeline = 0;
GLuint inputlayout = ...;
CODE
vertprogram = glCreateShaderProgramv(GL_VERTEX_SHADER, 1, &vs_code);
geomfragprogram = glCreateProgram();
// ...
glProgramParameteri(geomfragprogram, GL_PROGRAM_SEPARABLE, GL_TRUE);
glLinkProgram(geomfragprogram);
glGenProgramPipelines(1, &progpipeline);
glUseProgramStages(progpipeline, GL_VERTEX_SHADER_BIT, vertprogram);
glUseProgramStages(progpipeline, GL_GEOMETRY_SHADER_BIT|GL_FRAGMENT_SHADER_BIT, geomfragprogram);
CODE
glProgramUniformMatrix4fv(vertprogram, 0, 1, GL_FALSE, viewproj);
glProgramUniform2fv(geomfragprogram, 1, 1, pointsize);
glBindProgramPipeline(progpipeline);
glBindVertexArray(inputlayout);
glDrawArrays(...);
A használat elég intuitív, úgyhogy shader kódot nem is írok (pontokat rajzol ki a megadott méretben). Viszont az uniformokkal már megint mi történt... Szóval az új funkcionalitás miatt gyakorlatilag az összes glUniformXX függvényt meg kellett duplikálni glProgramUniformXX néven... Persze lehet, hogy a régi módszerrel is megoldható, viszont alapszabály OpenGL-ben, hogy nem keverjük a régit az újjal. Ha mégis szeretnéd, akkor a glActiveShaderProgram() hívást használd (ne a glUseProgram()-ot!). Sőt, a legjobb az, ha inkább uniform buffer-t használsz. Tovább általánosítható a shaderek használata az ún. szubrutinokkal. Régen, ha csak picit szerettél volna módosítani egy shader működésén, akkor vagy egy külön shadert írtál, vagy nekiálltál makrókat használni (az eredmény persze így is több külön shader program lett).
Gondolom feltűnt, hogy GL 4.3 szintaxissal írtam a példát; ezt csak kényelmi okokból tettem (az index megadható a shaderben), de persze a szubrutinok már GL 4.0 óta elérhetőek. Értelemszerűen olyankor az indexeket program oldalon kell lekérdezni a glGetSubroutineIndex() függvénnyel. Különleges dolog ebben, hogy meg kell adni a konkrét shader stage-et, amiben a szubrutin szerepel; hát persze, hiszen ez már nem a globális (shader) programra vonatkozik, hanem lokális az egyes shader szakaszokban! Némi magyarázat azért szükséges. A szubrutinok fejléceit előre kell deklarálni egy konkrét névvel, amire később majd hivatkozni lehet a shaderen belüli (kvázi) példányosításokkal. Értelemszerűen egy példányosítás a deklarált szubrutin egy konkrét implementációja (a kívánt logika szerint). A program oldalhoz való kötődés az ún. subroutine uniform-okkal valósul meg. Bár első ránézésre hasonló, ez nem egy szokványos uniform adat. Ugyanis a többivel ellentétben ennek nem location-t kell megadni, hanem (mint mondtam) a shader stage-et (és hogy azon belül mennyit akarsz beállítani). A bekezdés végén annyit mondanék, hogy bár a metál shader nyelve még mindig toronymagasan vezet, nem kell különösebb észrevétel ahhoz, hogy lássuk honnan lopott. Egyértelmű haszon azonban, hogy ezáltal könnyebb közös interfészt húzni a kettő fölé. Ez egy nagyon izgalmas dolog, ugyanis használható debug célokra is (pl. adott shader stage kimenetét visszaolvashatom), de van egy népszerű gyakorlati alkalmazása is, mégpedig a részecskerendszerek. Használható egyéb dolgokra is, Rákos Dániel például ezzel oldja meg a view frustum culling-ot instance-olt rajzolásra (nevet is adott a technikának: instance cloud reduction).
Shader oldalról rögtön a legújabb, GL 4.4-es megközelítést fogom használni, mert kényelmesebb (pl. a már említett új program API-ra van szabva). Az alábbi vertex-geometry shader páros generál új részecskéket:
A transform feedback azokat a kimenő értékeket fogja eltárolni, amikhez meg van adva xfb_offset. GL 4.4 előtt ezeket OpenGL oldalon kell megadni a glTransformFeedbackVaryings() függvénnyel, még a (shader) program linkelése előtt. Az xfb_buffer azt mondja meg, hogy melyik binding point-ban levő bufferbe kerüljenek az adatok (írhat ugyanis egyszerre több bufferbe is). Vegyük észre, hogy egyik shader sem ad ki gl_Position-t, sőt nem is adhat, mert ilyenkor a raszterizációt ki kell kapcsolni (GL_RASTERIZER_DISCARD). A bufferbe ugyanakkor konkrét primitívek fognak íródni (jelen esetben pontok). Most akkor térjünk át ennek a CPU oldali részére: CODE
GLuint emittersbuffer = ...; // ebben vannak a generátorok
GLuint particlebuffers[3] = { 0, 0, 0 };
GLuint transformfeedbacks[3] = { 0, 0, 0 };
GLuint inputlayout = ...;
GLuint emitpipeline = ...; // úgy, mint fent
GLuint updatepipeline = ...;
int currentbuffer = 0;
bool prevbufferusable = false;
CODE
// inicializálás
glGenBuffers(3, particlebuffers);
glGenTransformFeedbacks(3, transformfeedbacks);
for( int i = 0; i < 3; ++i ) {
glBindBuffer(GL_ARRAY_BUFFER, particlebuffers[i]);
glBufferData(GL_ARRAY_BUFFER, MAX_PARTICLES * sizeof(Particle), NULL, GL_STATIC_DRAW);
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, transformfeedbacks[i]);
glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, particlebuffers[i]);
}
CODE
// generálás (az új részecskék az utolsó bufferbe mennek)
glEnable(GL_RASTERIZER_DISCARD);
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, transformfeedbacks[2]);
{
glBindProgramPipeline(emitpipeline);
glBindVertexArray(inputlayout);
glBindVertexBuffer(0, emittersbuffer, 0, sizeof(Particle));
glBeginTransformFeedback(GL_POINTS);
{
glDrawArrays(GL_POINTS, 0, NUM_EMITTERS);
}
glEndTransformFeedback();
}
// ... folyt ...
A generálás az egyetlen hely, ahol a glDrawArrays() függvényt használom, onnantól a továbbiakat lehet közvetlenül a transform feedback-ből rajzolni. A részecskék frissítése, ahogy mondtam ping-pong stílusban történik: CODE
// ... folyt ...
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, transformfeedbacks[currentbuffer]);
{
glBindProgramPipeline(updatepipeline);
glBindVertexArray(inputlayout);
glBeginTransformFeedback(GL_POINTS);
{
// beleírom az imént generált részecskéket
glBindVertexBuffer(0, particlebuffers[2], 0, sizeof(Particle));
glDrawTransformFeedback(GL_POINTS, transformfeedbacks[2]);
// hozzáadom az előző buffer tartalmát
if( prevbufferusable ) {
glBindVertexBuffer(0, particlebuffers[1 - currentbuffer], 0, sizeof(Particle));
glDrawTransformFeedback(GL_POINTS, transformfeedbacks[1 - currentbuffer]);
}
}
glEndTransformFeedback();
}
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, 0);
glDisable(GL_RASTERIZER_DISCARD);
currentbuffer = 1 - currentbuffer;
prevbufferusable = true;
A kapott eredményből ezután már lehet billboard-okat csinálni és a megfelelő módszerrel kirajzolni. Füst esetén például a részecskéket előbb rendezni kell mélység szerint (pl. compute shader-rel), tűz esetén rögtön ki lehet rajzolni additive blending-gel. 
Tudni kell - és a kódból is látható - hogy a glDrawTransformFeedback() nem állítja be magától a buffert amiből rajzol; azt neked kell megcsinálni. Szintén ehhez kapcsolódik, hogy addig hibát fog dobni, amíg legalább egyszer fel nem lett töltve (ezért kell a prevbufferusable változó). Természetesen transform feedback-et is lehet instance-olva rajzolni, illetve mint említettem, ha több bufferbe (stream-be) lett kiírva az adat, akkor egy konkrét stream-et a glDrawTransformFeedbackStream()-mel lehet kirajzolni. A lekérdezések a hatékonyság érdekében ún. query object-ekkel vannak megvalósítva. A legtöbb ilyennek hatóköre (scope) van, ami egy glBeginQuery()/glEndQuery() blokkot jelent. Ezen blokkon belüli hívásokra vonatkozik a lekérdezés. Tekintsük át a lehetséges típusokat:
CODE
GLuint countquery = ...; // glGenQueries()
glBeginQuery(GL_TRANSFORM_FEEDBACK_PRIMITIVES_WRITTEN, countquery);
{
// a fenti transform feedback példakód
}
glEndQuery(GL_TRANSFORM_FEEDBACK_PRIMITIVES_WRITTEN);
GLuint count = 0;
glGetQueryObjectuiv(countquery, GL_QUERY_RESULT, &count);
Nem egy bonyolult dolog; naná, hiszen pont olyan példát választottam, amiben muszáj bevárnom az eredményt (CPU-n rendezem a részecskéket). Az optimalizált változat megírása höfö. Amíg megírjátok a bitonikus rendezést compute shader-rel (amit majd elküldtök nekem is), bemutatok egy GL 4.4-es új fogalmat, amit query buffer object-nek hívnak. Ez értelemszerűen arra való, hogy ne kelljen CPU oldalra lekérdezned az eredményt, hanem egyből vissza tudd etetni egy shadernek. Lássuk: CODE
GLuint countquery = ...; // glGenQueries()
GLuint querybuffer = ...; // glGenBuffers()
// ...
glBindBuffer(GL_QUERY_RESULT_BUFFER, querybuffer);
glGetQueryObjectuiv(countquery, GL_QUERY_RESULT, 0);
glUseProgram(...);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 0, querybuffer);
for( ... )
glDispatchCompute(...);
Nem is értem miért segítek nektek ennyit...így már csak a bitonikus rendezést kell megírjátok... Szintén elég hasznos dolog (és GL 3.0 óta elérhető) a feltételes rajzolás, ami a glBeginConditionalRender() hívással kezdeményezhető, viszont csak és kizárólag occlusion query-vel működik. Ez tulajdonképpen a régi változata az imént bemutatottnak. Az alábbi parancsokkal lehet vezérelni:
Ebben a bekezdésben is alapvetően egy régi (multi-draw) és egy újabb (multi draw indirect) technikáról lesz szó. A multi-draw arra való, hogy szelektíven rajzolj egy static batch-ből (pl. csak azokat az elemeket, amiket kiválasztottál). GL 2.0 óta elérhető, a használata pedig a következőképpen fest:
CODE
GLsizei counts[] = { obj1indexnum, obj3indexnum, obj52indexnum, ... };
const GLvoid* offsets[] = { obj1offset, obj3offset, obj52offset, ... };
glMultiDrawElements(GL_TRIANGLES, counts, GL_UNSIGNED_INT, offsets, ARRAY_SIZE(offsets));
Amit meg kell említeni, hogy ez a szelektív viselkedés nem feltétlenül hardveresen gyorsított: megeshet, hogy a driver csinál magában egy for ciklust, ami szinte egyenlő a konyha rajzolással (persze kevesebb driver overhead). Szóval nem kell sietni a szelekciórajzolás átírásával... GL 4.3-tól elérhető hasznosabb technika a multi-draw indirect, ami a static batching-et egyesíti a hardware instancing-al. Effektíve ez azt jelenti, hogy az azonos input layout-tal (és material-lal) rendelkező objektumaidat összepakolod egy bufferbe, a hozzájuk tartozó instance adatokat egy másik bufferbe, a rajzolóhívásokat leíró paramétereket pedig egy indirect buffer-be. Utóbbit nézzük meg: CODE
GLuint inputlayout = ...; // hasonlóan, mint instancing-nál
GLuint multibatchindexbuffer = ...; // 3 különböző objektumot pakoltam össze
GLuint instancebuffer = ...; // instance adat
GLuint indirectbuffer = 0; // indirekt rajzolóparancsok
CODE
glGenBuffers(1, &indirectbuffer);
glBindBuffer(GL_DRAW_INDIRECT_BUFFER, indirectbuffer);
glBufferData(GL_DRAW_INDIRECT_BUFFER, 3 * sizeof(DrawElementsIndirectCommand), NULL, GL_STATIC_DRAW);
DrawElementsIndirectCommand* cmddata = glMapBuffer(GL_DRAW_INDIRECT_BUFFER, GL_WRITE_ONLY);
{
cmddata[0] = ...;
cmddata[1] = ...;
cmddata[2].count = obj3indexnum;
cmddata[2].instanceCount = obj3instancenum;
cmddata[2].firstIndex = obj1indexnum + obj2indexnum;
cmddata[2].baseVertex = 0;
cmddata[2].baseInstance = obj1instancenum + obj2instancenum;
}
glUnmapBuffer(GL_DRAW_INDIRECT_BUFFER);
CODE
// rajzolás
glBindVertexArray(inputlayout);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, multibatchindexbuffer);
glBindBuffer(GL_DRAW_INDIRECT_BUFFER, indirectbuffer);
glMultiDrawElementsIndirect(GL_TRIANGLES, GL_UNSIGNED_INT, 0, 3, sizeof(DrawElementsIndirectCommand));
Világos, hogy ezzel a fajta megoldással lényegesen kevesebb memória felhasználásával oldhatóak meg kombinált instancing feladatok. Természetesen ugyanazok a meggondolások vonatkoznak erre is: a textúrákat atlaszba kell pakolni, a címzési módokat pedig emulálni (ha szükséges). 
Egy GL 4.0-tól elérhető előzetese ennek a glDrawElementsIndirect(), ami csak annyiban kevesebb, hogy egy objektumot tud indirekt paraméterekkel rajzolni. Na oké, de miért jó az, hogy a paraméterek a GPU-n vannak? Most mindenkinek felcsillan a szeme: mert előállíthatom shaderből is (akár compute shader-rel [SSBO-ként leküldve] vagy transform feedback-kel)! Zárójelben mondom, hogy létezik GL_DISPATCH_INDIRECT_BUFFER is, amivel compute shader-ekre lehet hasonló hívást tenni; ebben az esetben a workgroup méreteit tartalmazza. Multi-dispatch egyelőre nincs (nem is világos, hogy kell-e). És ezzel elérkeztünk az OpenGL 4.6 "újdonságához" (amiről megbeszéltük, hogy nem az): nagyon szép, hogy a shader is elő tudja állítani a paramétereket, na de mennyit állított elő? Lekérdezhetem természetesen query-vel vagy atomic counter-el, de az megakasztja a CPU-t. Az új kiterjesztés (GL_ARB_indirect_parameters) célja az, hogy ezt a lekérdezést is megússzuk, így a teljes indirekt rajzolás átvihető a GPU-ra.
(megj.: a barrier-ek közül a Khronos kifelejtette a GL_PARAMETER_BARRIER_BIT-et, de elvileg már tudnak róla) Az új rajzolóhívás értelemszerűen egy offsetet vár a parameter buffer-be, illetve meg kell neki adni egy maximális rajzolóhívásszámot (ha esetleg többlet van a bufferben, azt figyelmen kívül hagyja). Az eddig áttekintett (vagy csak megemlített) módszereket ötvözve arra a konklúzióra juthatunk, hogy egy modern megoldással tisztán a GPU-ra lehet áttolni valamilyen funkcionalitás (akár teljes) életciklusát. Persze ez a rengeteg új tudás gyönyörűen változatos bugokat tud előidézni. Az első debug módszert úgy hívják, hogy AMD kártyán fejlesztés (ha az nincs, akkor Intel is jó). Ugyanis az nVidia driver beképzelt módon sokkal okosabbnak képzeli magát nálad:
Mert ilyen rendes. Aztán átviszed a programodat egy másik gépre, ahol szanaszét száll, és persze az AMD és az Intel drivereit fogod szidni, hogy milyen ótvarok (ez a "nálam működik" nevű kifogás 3D grafikai megfelelője). Az AMD driver nem ilyen pirított ribanc módjára viselkedik, hanem hozzád alkalmazkodik: ha hülyeséget mondtál neki, akkor hülyeséget fog csinálni. A hülyeségek megtalálásához pedig nagyon hasznos debug eszközök léteznek. GL 4.3 óta például ott van az ARB_debug_output, ami hasonlóan működik mint vulkánban, tehát azonnal szólni fog ha egy klasszikus OpenGL hibát vétettél, de akár tippeket is adhat neked, hogy mitől lehet hatékonyabb a programod. CODE
static void APIENTRY ReportGLError(
GLenum source, GLenum type, GLuint id, GLenum severity,
GLsizei length, const GLchar* message, const void* userdata)
{
__debugbreak();
}
CODE
glEnable(GL_DEBUG_OUTPUT);
glDebugMessageControl(GL_DONT_CARE, GL_DONT_CARE, GL_DONT_CARE, 0, 0, GL_TRUE);
glDebugMessageCallback(ReportGLError, 0);
Mint mondtam, a kontext létrehozásakor meg kell adni a WGL_CONTEXT_DEBUG_BIT-et. Mivel macOS-en nincsen GL 4.3, ott ezt nem használhatod (cserébe normális debug eszköz sincs). Windows-on két különálló debug programot emelnék ki. Az egyik az AMD CodeXL, ami a már régóta halott gDebugger örököse. Egyetlen dologra használom: a hibaüzenetek elkapására. Másra ugyanis teljesen használhatatlan (leginkább lefagy). A breakpoints menüben a debug output-nál lehetőleg mindent jelölj be. Egy mérföldekkel jobb program a RenderDoc, ami bár OpenGL-el limitáltan működik (csak core profile, nem tud shadert debugolni) még így is felülmúlja a néhai PIX-et. Annyi megszorítás van, hogy a program 64 bites kell legyen, illetve ahogy mondtam, ha több kontext van, azokat meg kell osztani. Képes megmutatni a teljes pipeline állapotát az egyes rajzolóhívásokban, azon belül megnézhetőek a buffer/textúra tartalmak, sőt a geometria adatokat a Mesh Output fülön meg is jeleníti (a navigáció kicsit hektikus, de szokható). 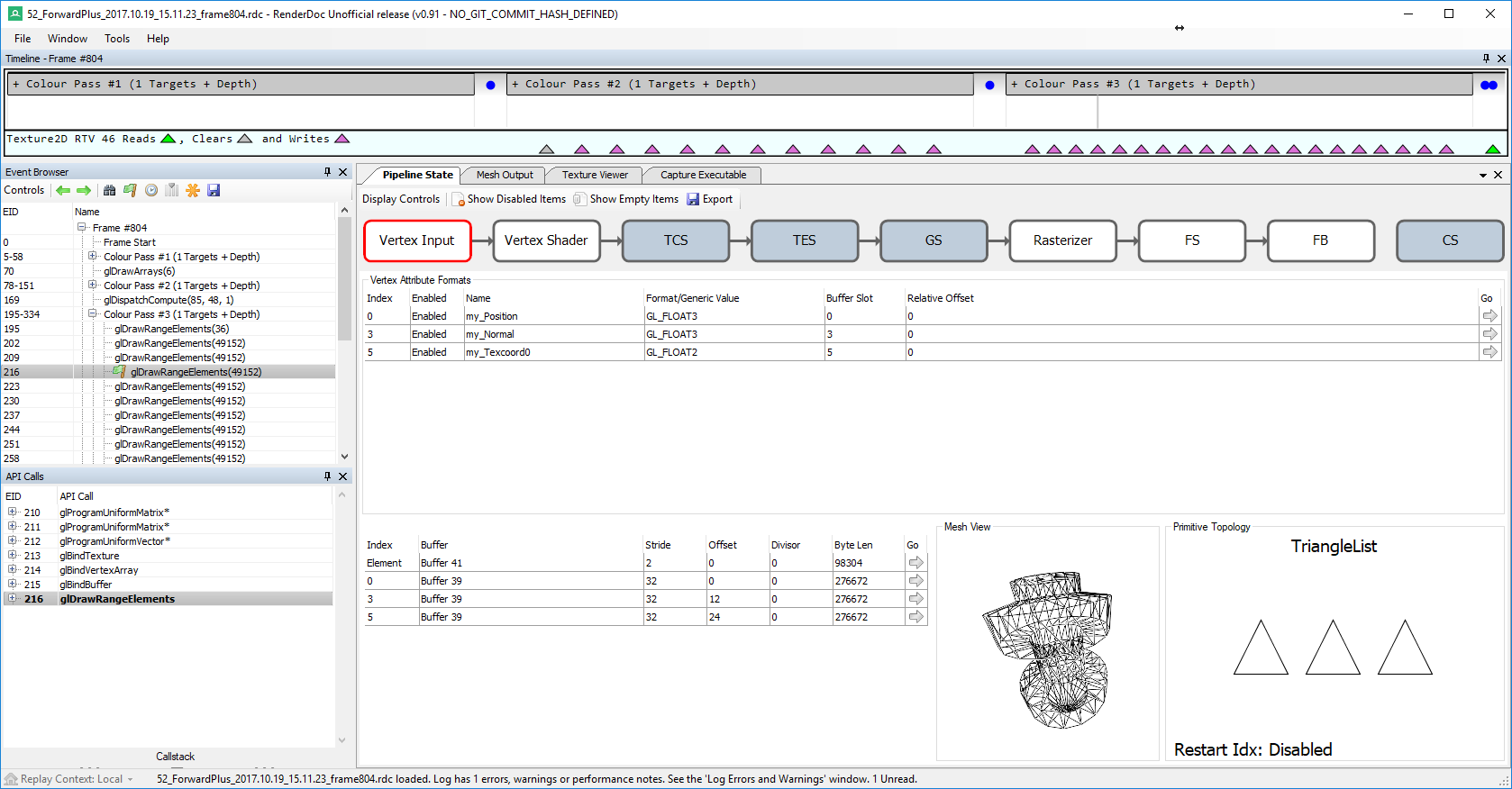
Különösen tetszik, hogy a Texture Viewer fülön megtekinthető a framebuffer aktuális állapota az összes létező attachment-jével. Külön állítani lehet, hogy pl. milyen tartományban mutassa a depth/stencil buffer tartalmát, és persze tetszőleges pixelre meg tudja mondani az értékeket. Meg egy csomó egyéb dolog. Annyi hátránya azért van, hogy driver hibákkal nem foglalkozik, szóval ha a driver bugos, akkor azt egy elszállással fogja jutalmazni. Ilyenkor állíts be kb. 20 másodperc várakozást és csatlakozz rá a programra Visual Studio-ból. Ha te fordítottad le az eszközt, akkor könnyen megtalálható, hogy mi okozta a driver hibát (én kénytelen voltam átírni a kódját, hogy megkerülje valahogy). Na de mi a helyzet macOS-en? Tulajdonképpen az egyetlen valamire használható debug eszköz az OpenGL Profiler, amit külön kell letölteni a fejlesztői oldalról. Lehetőleg mindig a legújabbat töltsed le, még ha béta is, ugyanis ami neked kellene az sosem működik. Hibákat ez is el tud kapni, illetve rá lehet állni tetszőleges OpenGL hívásra; ekkor meg tudja mutatni a buffer/textúra tartalmakat. Szódával elmegy, de nem mondanám túl okosnak. Helyette használható még az apitrace, de körülményes a beállítása és a használata... Ha minden más kudarcot vallott, akkor próbálkozhatsz vele. Ha ez se segít, akkor marad a zseniális printf() nevű találmány. A leírt technikákra bár adtam konkrét példákat (a szokott helyen), az alkalmazási területeik ennél sokkal messzebbre nyúlnak; természetesen az adott applikációra kell ezeket szabni. A célom az, hogy tudjatok ezekről, amikor egy új alkalmazást szeretnétek fejleszteni (vagy egy régit gyorsítani), ugyanis a GPU ezen új API-k által valóban használható általános célú programozásra; különösen fontosnak tartom emiatt, hogy legalább fogalmi szinten meglegyenek ezek a dolgok nem csak a GPU programozók fejében.
Irodalomjegyzék https://www.khronos.org/registry/OpenGL/specs/gl/glspec46.core.pdf - OpenGL 4.6 specification (Khronos, 2017) https://www.khronos.org/registry/OpenGL/specs/gl/GLSLangSpec.4.60.pdf - GLSL 4.60 specification (Khronos, 2017) https://www.khronos.org/opengl/wiki/ - OpenGL Wiki (Khronos) http://web.engr.oregonstate.edu/~mjb/.../tessellation.1pp.pdf - Tessellation Shaders (Oregon State University, 2017) https://www.seas.upenn.edu/~cis565/.../GPU%20Tessellation.pptx - GPU Tessellation (University of Pennsylvania, 2010) |
